Architecture
Overview
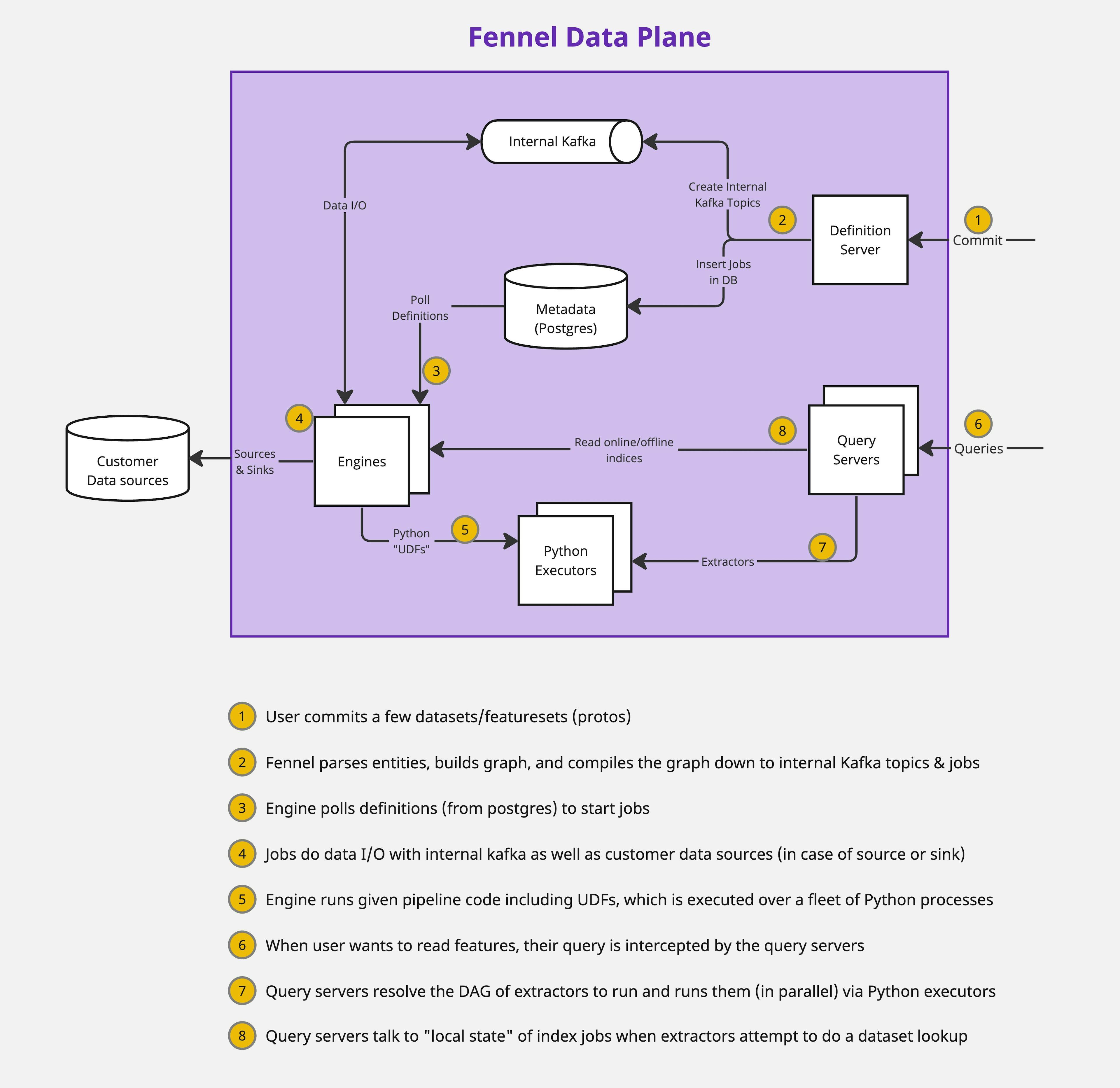
Here is a simplified view of Fennel's data plane architecture:
Compiling Commit to Jobs & Topics
During commit, the client converts all datasets and featuresets into protobufs and sends those over to the Fennel dataplane. Within the dataplane, a service called definition server intercepts the request.
Definition server builds an entity graph out of the protobufs (e.g. dataset, pipeline, features etc are node and edges between them representing various kinds of relationships) and does a bunch of validations on the graph - these validations encode, for instance, that it's invalid to mutate a pipeline without incrementing the dataset version.
Assuming all validations pass, the graph is converted into blueprints - the logical description of the physical assets (like Kafka topics, internal jobs) that need to be created. Then, a bank of all existing physical assets is checked to see if an isomorphic asset already exists (say created via another branch). Either way, ref-counts for all assets are incremented/decremented and any new desired assets are created and any unwanted assets are destroyed.
Atomicity of Asset Changes
Once the system knows the list of physical assets to create, actually materializing them is rather challenging. In fact, there are three key constraints on this process:
- It involves talking to systems like Kafka, Postgres etc, any of which can fail for any reason at any point in time
- The commit either succeeds and all new assets are created or it fails and nothing should change (i.e. no new stray assets)
- If commit requires decommissioning of assets (say Kafka topics), it can't be destroyed until the rest of the commit has succeeded, else existing state will be lost.
Fennel creates a Ledger of all asset creations and a separate ledger for asset destructions - and this ledge is able to provide pseudo-atomicity guarantees. Further, Fennel interleaves these ledges with some Postgres transaction semantics in order to satisfy all the three constraints.
Overview of Core Engine
Fennel runs a replicated fleet of "engines" - service that does the heavy lifting of all compute. These engines are polling Postgres to read any changes to job definitions (aka Job Registry) and spin up corresponding jobs. See core engine to learn more about the inner workings of the engine.
Query Read
Any request to read feature values is intercepted by an auto-scaling fleet of query servers. These servers, at any point of time, have a pre-computed graph of all the entities (like datasets, features, indices etc.) that exist. Upon intercepting a query request, they convert the query to a physical plan - the order in which extractors must be run to go from the input features to the output features.
As part of executing the physical plan, these query servers run extractor code via a fleet of Python executors and lookup indices by reading the state of jobs running on engines.