If someone were to write a biography of an ML model, it would read like this — the model looked very promising during training. Teams building it got excited and spent a few months shipping it to production, only to discover that it doesn’t perform as well in production. After a couple of failed attempts at improving the production performance, the model was abandoned.
Unfortunately this sad story is far too common in practice. But it doesn’t have to be like this. In this post, we will look at the most common reason why this same story plays out over and over again. That reason is “online offline feature skew”, or rather more accurately called as "training-inference skew". But before discussing why it’s so hard to replicate training performance in production, let’s stop and ask ourselves - why do we expect to be able to do this in the first place?
The Math of Model Generalization
The math behind ML assumes that the probability distribution of the features seen at the training time is identical to the distribution of features seen at the inference time. In other words, the same mechanism is generating the data at both training and inference time. As long as that happens, training eval performance is expected to carry over to prediction for unseen examples.
But all bets go off when the distribution of features between training and inference start skewing. And at that point, the link between training performance and the performance in production breaks down. This is scary because training performance is often the only reliable compass that points to the true north of production performance. And so when this compass also becomes unreliable, a data scientist could train a model that looks really good at training time and yet have no way of knowing if it will do well against the distribution of data at inference time or not. Absence of a reliable indicator makes it virtually impossible for them to actually drive up the performance of models in production.
And that my friends is the meaning of training inference skew — divergence in the distribution of features between training and inference. Note that sometimes people use the word “online offline skew” to describe it but that’s just a special case of more general training/inference skew (as we will see in more detail soon).
Causes of Training Inference Skew
Okay so how to avoid training inference skew? Well, we need to identify and eliminate all the causes of training inference skew. What could cause inference training skew? Good question. Turns out so many kinds of things - some more subtle than the others. Here is a list of 8 most common causes of this skew:
- Online offline skew
- Changes to upstream pipelines
- Failure of upstream failures
- Time Travel
- Stale data
- Changes to feature definitions
- Feature drift
- Self Feedback
Let’s review these these one by one and also look at how to prevent these from happening:
1. Online offline skew
This is the more well known special case of training inference skew that shows up primarily in realtime feature/model serving scenarios. Training requires lots of data and hence is a throughput constrained big data problem better handled by SQL pipelines written on top of warehouses. Whereas online serving is latency constrained and is better handled by same technologies used to build the rest of the app - say a general purpose language like Python/Java along with relational stores or in-memory key-value stores like Redis. With such a setup, it’s very easy for definitions to become subtly different leading to feature skew. This, in our experience, is extremely prevalent across teams and is one of the top reasons why offline promising models don’t perform that well in an online setting.
Preventions
- Having a single codepath for extracting features across training & inference
- If possible, logging the features at the serving time and using only the logged data for training.
2. Changes to upstream pipelines
Let’s say the feature depends on the output of a pipeline which in turns depends on another pipeline. When the feature is developed and model is trained, everything is working perfectly. But the author of that parent pipeline changes it at a later time. Here are a few failure modes depending on the nature of the change:
- The parent pipeline is simply deleted - in this case, the downstream data isn’t updating at all so either becomes stale or is full of Nulls/default values. In either scenario, the distribution of feature values has shifted.
- The parent pipeline’s semantics change a bit - enough that the semantics & distribution of the downstream feature also change.
- The parent pipeline’s cadence changes - instead of running every hour, it now runs every day. This makes the data a tad bit more stale and have a slightly different data distribution. Once again, enough to subtly degrade model performance without breaking anything outright.
- The parent pipeline changes so that the schema / data type / format of the output table changes (e.g. a column that is supposed to represent timestamps earlier had seconds since epoch and now has datetime strings so downstream pipelines fail). Such changes break the feature extraction logic which may be programmed to falling back to NULLs or default values.
Preventions
- Immutability - making resources (e.g. datasets, pipelines) immutable so that they can't be changed unless an explicit flag is provided by a human
- End to end lineage validation — when a pipeline is defined, it should be verified that all upstream data sources/pipelines also exist and have the correct types.
- Not suppressing errors, especially typing errors, while building ML features.
3. Failures of upstream pipelines
Data pipelines fail. That’s just a reality of life. Every time a pipeline fails, depending on how it is written, it either results in delayed data (which in turn messes with data freshness/distribution for downstream feature engineering) or outright incorrect data (e.g. NULLs get written out). Both create skews in feature distribution and hence are bad outcomes. So why do pipelines fail? There are two common reasons (along with a long tail of ad hoc reasons):
- Data volumes increase over time and pipelines start going out of memory (maybe not every time but sporadically, which makes this problem even worse).
- Some bug in software - say some assumption isn’t met, typing is wrong, overflow happens etc. The challenge here however is that pipeline may get “stuck” - the scheduler may try to run it again and again and each run encounters the same error. This could create a backlog leading to altered distribution.
Preventions
- Building realtime pipelines that operate on micro batches of data and are thus relatively immune to OOM issues.
- Writing pipelines in a way that avoid a) large memory state and b) large memory reshuffles. While writing the pipelines like this is harder, it goes a very long way in avoiding OOM issues.
- Executors/schedulers that know how to selectively ignore a failing data point after couple of retries instead of blocking the whole pipeline.
4. Time Travel
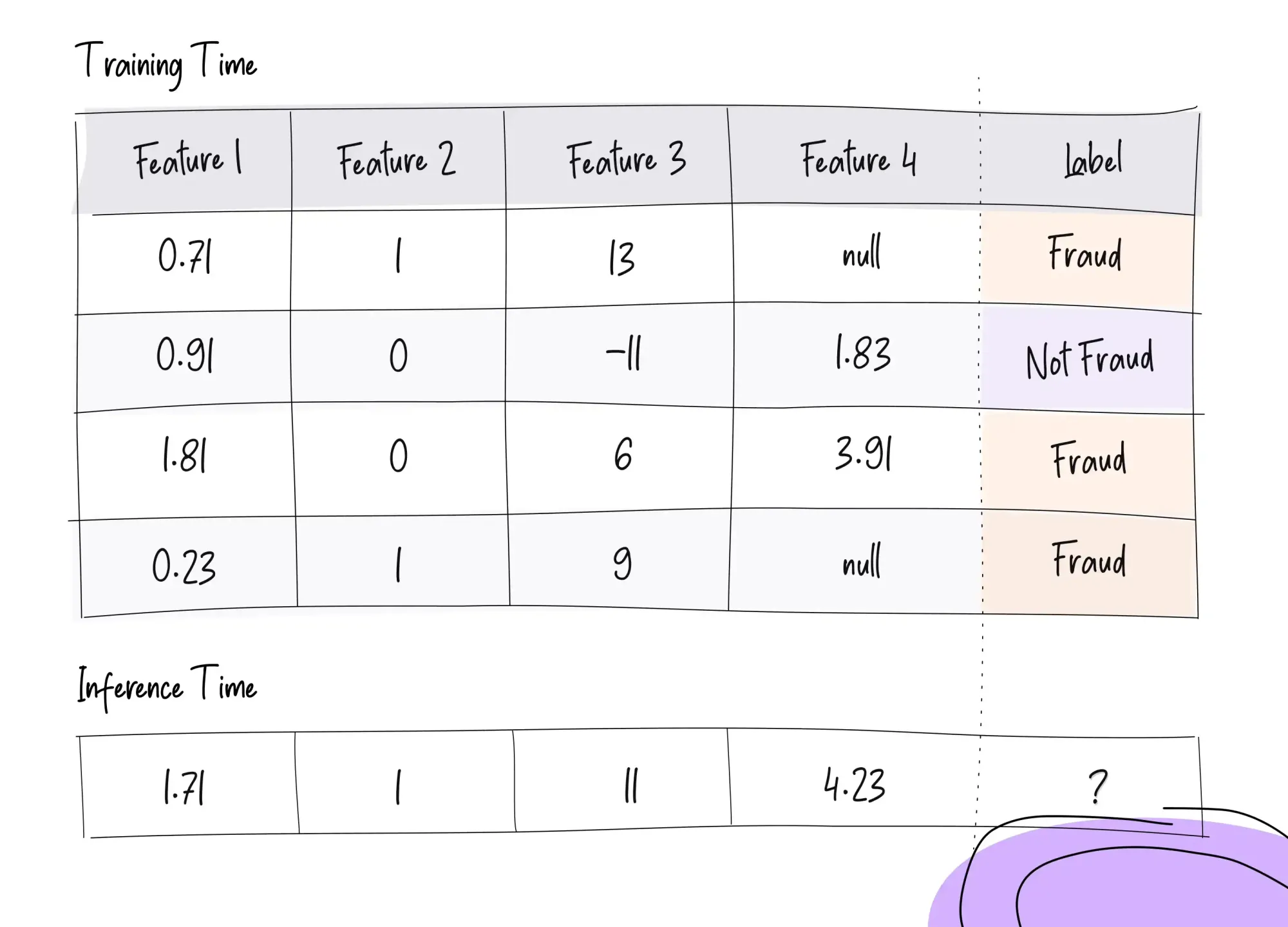
Imagine that one of the features in a credit card fraud detection model is the number of times the user has done a transaction with this particular vendor. Now say that a given user does three transactions with a vendor - one on Monday, one on Tuesday and one on Wednesday. If we were running a fraud detection algorithm before approving the transaction, the algorithm should ideally be seeing the values 0, 1, and 2 respectively for this feature.
Now imagine that we try to train a model on Thursday using a training dataset of millions of transactions also containing these three transactions. If the training data generation code looks at the current state of the world on Thursday, the extracted feature values might be 2, 2, 2, which is clearly incorrect. Instead, we should have looked at the state of the world asof the time when the transaction happened — because that is what the model would have seen at the inference time.
This is the issue of time travel - information is leaking from the future events into the training data examples of older times and creates a skew between training time features and inference time features. This is REALLY REALLY bad and can single handedly destroy the performance of the model in production. Unfortunately, in our experience, almost all cases that involve online model inference end up suffering with time traveling.
Preventions
- Having a data management system that supports asof queries to get the value of a feature as of a correct point in time.
- If building asof is too hard, a simple alternative is to simply log the feature values at the time of online inference and train models only using those logs. This however can slow down the testing of a new feature idea and may be unacceptable in some domains. See our previous post on time travel and information leakage for details.
5. Stale Data
As noted in this post about realtime ML, making ML systems realtime leads to significantly better predictions. But still, using non-realtime features may be suboptimal, but isn’t buggy per se. However, there are situations where using stale data is sort of buggy too. Let’s look at one such case:
Let’s say that features are generated once a day by a batch pipeline and uploaded to a key-value store (say Redis). Through out the day, whenever online inference needs to be done, first features are loaded from Redis and then passed to a model inference service. So for some predictions, features are relatively fresh (say towards the start of the day) and for some other predictions they are upto 24 hour stale (say towards the end of the day). However, when the model is trained, ALL training examples have the same staleness (often close to zero since features are extracted just before the model training step). This leads to the distribution of features in training and inference to diverge and happened quite simply because of the data staleness. As a result, models despite looking great in offline training, don’t perform as well.
Prevention
- Match feature generate cadence with prediction cadence. In particular, if online inference is involved, either log features at inference time for training or recreate feature values asof the time of inference.
- Making ML features realtime is a general good practice to improve model performance and can also help with this issue.
6. Changes to feature definitions
Like all other software, ML features can be buggy too. When that happens, the natural thing to do is to fix the bug. However, that crates a subtle issue with data quality. Part of the training examples were served using the older buggy definition of feature and the remainder along with inference will be served using the new definition — the classic case of training/inference skew. Not only this, it’s also common for ML features to depend on other ML features — e.g. changing feature f will change its log transformation feature too. And so feature skew could spread to other derived features too.
Prevention:
- Make all feature definitions immutable (or at least explicitly versioned if mutations are allowed).
- If a bug is discovered in a feature, it might be best to fix it and just train a new model with the fixed feature values.
7. Feature Drift
Even when the whole ML Platform is working as expected, the real world can change leading to changes in features via data. As an example, AC sales are high in summers and low in winters. If we had a feature that counted the number of AC sales in the last week, the feature distribution will change over time. This is often called as feature drift and is a natural part of the real world. When features drift, the trained model loses performance (after all model was fit to explain the patterns seen at the time of training and depending on how it is built, if it was trained in summer, it may continue to recommend ACs in winters too).
In our experience, natural feature drift (vs a drift caused by a bug) is often one of the more benign causes of training/inference skew. And really the best way to handle it is just retraining the models often.
Preventions
- Some way of measuring feature drift over time
- Retraining the models often - if not every day in an automated manner, at least once every few weeks.
8. Self Feedback
An extreme case of drift appears appears when a new model makes a large difference to the customer behavior, for instance, when launching the very first ML powered recommendations. In such cases, the launch of the model changes customer behavior which in turn changes the content getting distribution, resulting in the distribution of examples skewing very far away from the training data.This is slightly different from many other kinds of skew mentioned above - here the feature values for the given item are not skewing but the items that constitute the training data themselves are getting skewed. Nonetheless, the effect is the same - the model looks really good at training and also does well at small rollouts but the performance begins to erode when rolled out to larger traffic segments.
Prevention
- Retrain the model on new data capturing updated customer behavior
Feature Platforms & Training/Inference Skew
Given the cost of feature skew and the surface area of causes, it is best handled at the level of ML platform itself instead of expecting each data scientist to avoid it for each feature they write. But since this work isn’t super sexy, feature skew and other kinds of data quality issues are often not given due attention in far too many in-house feature platforms. That’s where professional feature platforms come in.
Many (but not all) professional feature stores are often built in a way to reduce at least the online offline feature skew. And while that’s a huge help, as we have seen above, there are many other causes of skew too which go unaddressed. For instance, some feature stores (like Feast) only do feature serving but don’t manage feature computation and so have no way of preventing changes to feature computation pipelines.
That’s why we, at Fennel, went a step above and elevated data quality to be a foundational architectural goal from the beginning. As a result of this focus on data/feature quality, Fennel’s feature platform is able to prevent/diagnose ALL of the above and many more kinds of feature skews and other data/feature quality issues. You can read more about it on Fennel docs or reach out to us for a demo.
Conclusion
Hope it helps you understand how to ensure that the performance of your models carry forward from training to production settings. Eliminating training/inference skew is challenging because it comes in many different flavors (one of which is the more well known special case of offline/online skew). And so great care must be given in architecting ML platform to avoid these.