A very powerful trend is playing out right now — more and more top tech companies are making a larger part of their machine learning as realtime as possible. So much so that many are skipping the offline phase [1] and directly starting with realtime ML systems. More specifically, the trend is to make the following parts of the ML stack realtime [2]:
- Model scoring. Precomputing the model’s decision for each user/request every day used to be a rather common approach until very recently. But this has mostly gone out of fashion now in sophisticated ML shops and has been replaced with model scoring happening online in the live request path.
- Feature extraction. Earlier features used to be computed via daily pipelines. Now a much larger % of these are being replaced with stream processing-based realtime features. Note that this is a strict superset of model scoring — if the features are realtime, it’s impossible to precompute model scores. But it’s still possible to do online model scoring with batch features.
In this post, we’ll look at the top seven reasons why this trend is playing out. But first, let’s first establish a common ground for what we mean by offline machine learning and how it is different from realtime machine learning.
Definition: Offline ML vs Realtime ML
A machine learning system is considered offline if the decisions are based on relatively stale information — say hours/days old. Often offline ML is implemented as a cron/pipeline that runs once a day and computes all the decisions. In contrast, an ML system is realtime when most of the decisions are made using fairly realtime information (e.g. lag of a couple minutes at most). Such systems often can not be implemented via traditional batch pipelines and cron jobs.
Seven Reasons For Using Realtime ML
- Cold Start of Users/Inventory
- Long Tail Predictions
- In Session Personalization
- Logged Out Users
- Experimentation Velocity
- Hardware Cost
- Simplicity of the Stack
Let’s go through these one by one
1. Cold Start Of Users/Inventory
In the offline world, by definition, decisions are based on stale data and are computed periodically, say once a day. This may work well for most users & items, but for a lot of products, new users are signing up all the time. It’s a known fact that the first couple of experiences have a particularly strong impact on users’ long-term retention. So personalizing any user’s first couple of experiences is crucial. But this user ID did not even exist when the batch job last ran a few hours ago. And so, offline systems cannot provide any degree of personalization to these users, which is very costly for the product’s long-term growth/revenue.
The same phenomenon plays out for cold-start inventory as well. Let’s say a news story appears in a news product — it’s simply unacceptable for it to not get any distribution whatsoever for a whole day. News is obviously an outlier example, but the same thing happens to varying degrees in lots of other verticals as well. As another example, it’s a well-known fact that in any marketplace, the first experience of a seller matters a great deal in them coming back for more later — and so it can be a very powerful experience if a seller uploads a product (or content in the content world) and gets some engagement (e.g., clicks, likes, orders) right away within a few minutes.
Realtime ML systems have a natural edge for handling cold-start scenarios like this, which compounds over time and can create a vastly superior long-term lift.
2. Long Tail Predictions
Even for users who aren’t cold per se, a vast majority of them will not be shopping on your e-commerce website every day. Most consumer internet products have a power law distribution where on one side, some people are a lot more active than others, and yet the bulk of the activity lies in the long tail.
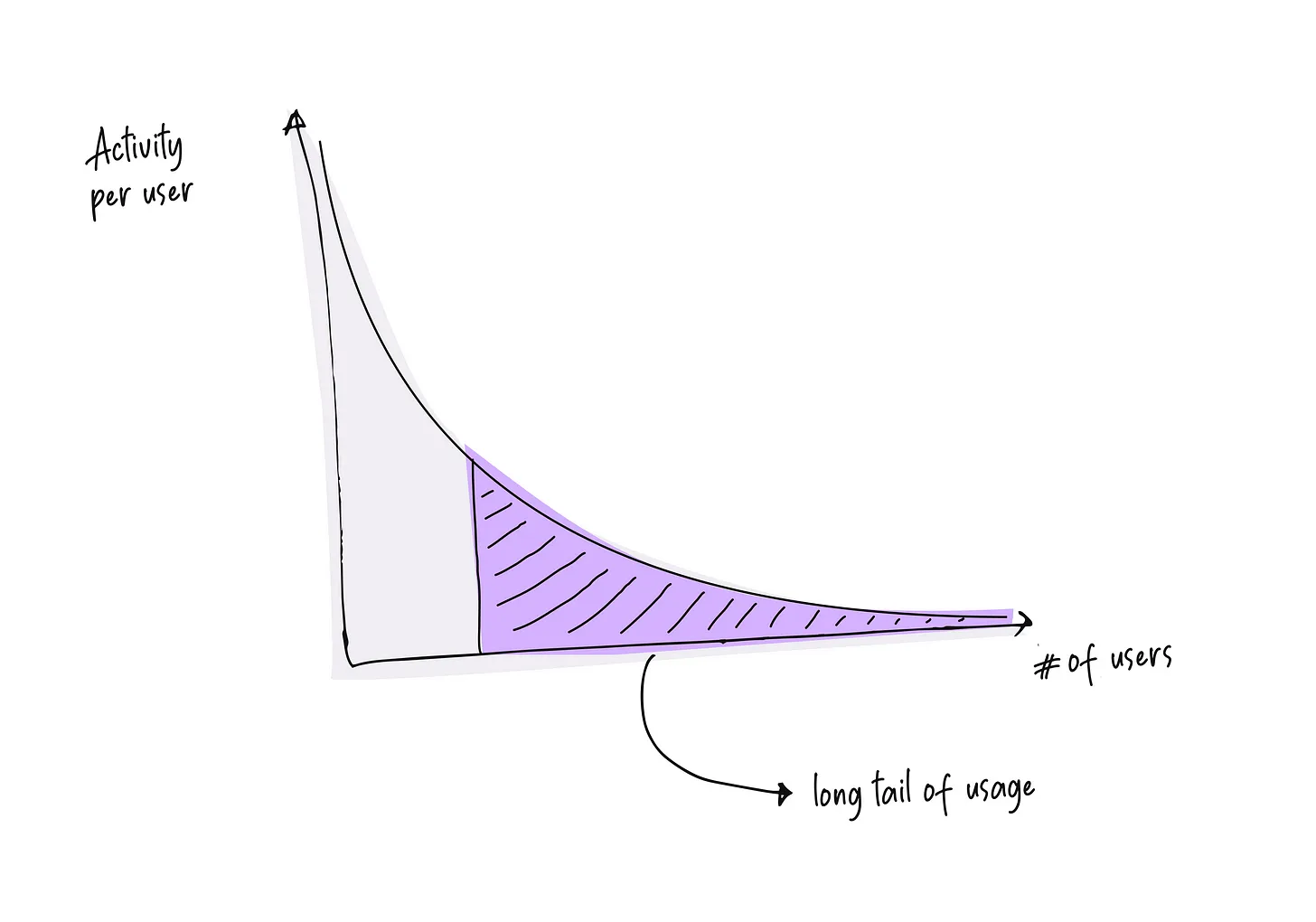
Let’s focus on a particular user who has visited your product twice before, the last visit being a month ago. Now imagine that this user shows up today — they will spend a few minutes trying to find whatever they are looking for, and if they can’t find it, they will eventually get frustrated and give up. If the ML system was offline, it only has access to two data points in their browsing history, and even those two data points are fairly old. However, the realtime system can instantly take their latest interactions in context — and going from 2 to 3 data points for personalization is literally 33% more data. Unsurprisingly, realtime systems significantly outperform their offline peers for long-tail.
Now, this would have been a boundary case if most of the users were daily active users and we had hundreds of data points about each — in that case, not including a data point for a day or so would not matter as much. But unfortunately, that is not the situation most products find themselves in — the bulk of their usage is from a collection of an extremely long tail of users.
The same phenomena plays out in most kinds of predictions. Let’s say you’re trying to build a system to detect credit card fraud. Some of the most powerful signals in such a system are counters quantifying the user’s past shopping history — e.g., how many times the user has bought something from this vendor. And since many of these are sparse (e.g., there is a long tail of restaurants where I have shopped just 1-2 times), realtime systems enjoy the exact same benefit over their offline peers.
3. In Session Personalization
Even when a user is using a product frequently, they often come to the product with different micro intents. Maybe on a Thursday night, the user is tired from their long workday, and they just want to listen to soothing jazz music. But the same user may be interested in high-energy pop music on a weekend morning. Realtime systems are capable of taking user's behavior and using that to personalize their experience of the same session - literally within seconds. In fact, this is one of the many reasons why TikTok as a product is so powerful — they have very much mastered the art of in-session personalization.
Empirically it has been found that in-session personalization generates a very meaningful lift in all sorts of usage metrics. And the best part of good in-session personalization is that it works not only on long-tail users but also on some of the most actively engaged users. Even outside of pure numbers, the products that do in-session personalization seem more responsive and less tone-deaf, and so the qualitative experience of using them is vastly superior. While in-session personalization is a relatively advanced technique, my prediction is that in a couple of years, many more products will be leveraging in-session personalization — it’s just that powerful.
4. Logged Out Users
Many products have a logged-out experience where the user can browse the website without creating an account. And often, the goal of such a logged-out experience is to convert users to make accounts and become more active users. Unfortunately, since these people don’t even have an account, it’s impossible for any batch system to precompute decisions for such logged-out users. However, realtime systems handle even this case very gracefully — it’s possible to do some personalization, not based on past history but based on their activity within that single session. When done right, the effect of this is that the experience improves substantially, and their odds of converting to registered active users go up significantly, which compounds over time and can create vastly different product trajectories in terms of growth.
5. Experimentation Velocity
Most ML systems today are not built once and then put in maintenance mode. There is so much low-hanging fruit usually that constant iteration/experimentation is needed to extract value. A common pre-conceived notion is that offline systems are “easier” to work with in comparison to realtime systems. But in practice, the experimentation velocity of offline systems is much worse for multiple reasons. Here are some of them:
- Offline systems by definition, run periodically, say once a day. As a result, if a new experiment needs to be started, it has to wait several hours before it can even go live.
- A far too common scenario is that an experiment is setup, but some sort of bug is discovered in the set up the moment it starts receiving traffic. In an offline system, the bug isn’t discovered potentially until the next day. And then, even if the fix takes 10 minutes, the fixed version can not be deployed for another day. Assuming most experiments take 7 days, just this issue can introduce a ~30% slowdown in iteration velocity.
- By definition, offline systems try to precompute all the decisions. But it’s a lot of computation and storage to compute all the decisions — and that cost scales linearly with the number of experiments that are running. As a result, most teams that use the offline system have a limit on how many experiments / variants can be run in parallel. This cap slows down the total throughput of experimentation which in turn leads to metrics not improving as fast as they could. Realtime systems have no such limitation, and so they can run many more experiments in parallel, resulting in a faster learning cycle.
- It is a lot harder to debug an offline system. A complex mesh of large batch pipelines ran 7 hours ago, and now you want to debug why is a particular user getting a particular recommendation — well, good luck debugging why it is happening. In realtime systems, on the other hand, it is often trivial to lift up the hood and inspect the interaction of any two parts of the system, often with something as simple as print/log statements.
I can go on and on with more examples, but anyone who has worked on both an offline ML system and a realtime ML system will tell you this — the iteration velocity with realtime ML system is significantly higher. And that extra iteration speed results in much more powerful systems over time.
6. Hardware Cost
Offline systems require pre-computing ML features/models for every user. But for most products, a heavy majority of their registered users don’t show up every day — in fact, a majority of them don’t show up for days/weeks in a row. So all this computation/storage that was done to precompute results for such users was wasteful — and even though each unit of offline computation is “cheaper” than each unit of online computation, the much higher volume of offline computation more than makes up for it.
Some people attempt an optimization where they pre-compute the results only for users who are likely to show up today — for instance, they may pre-compute the results only for weekly active users. While this reduces the cost a bit (but is still super wasteful), it runs into another problem - what if a user who we thought would not come to show up actually shows up? We don’t have any precomputed results and so have to fallback to a very naive system for them (e.g., time-sorted results). But one could argue that taking users who are not already active and making the more active is one of, the more important jobs of any personalization engine. And so this approach doesn’t work well in practice.
Let’s look at a more extreme example of this. When you go on the LinkedIn profile of a user, a sidebar shows up containing a list of similar users. However, ideally, this ranking of profiles on the sidebar will be personalized to the viewer. If we were to precompute the decisions of this system, we would need to precompute O(NxN) decision where N is the number of users on LinkedIn — the first factor of N for the profile that is being viewed and the second factor of N to account for viewer based personalization. This number grows so ridiculously fast that it’s impossible to do this pre-computation even for very small companies that have a mere 100K users, let alone anything bigger than that.
7. Simplicity of the Stack
As you might have noticed in several examples above, a purely offline ML system is quite simply impractical. So a lot of teams that start with an offline system quickly find themselves in a situation where some part of the stack is offline, and some part is realtime. For instance, maybe results are computed offline and at the request time, all the items that are out of stock are filtered out. Or maybe results are pre-computed for only daily active users, but if any other user shows up, their results are computed on the fly. Or maybe results are generally precomputed offline, but special logic is needed to give a good first impression to cold-start users.
Each such bandaid makes the system harder and harder to reason about. And eventually, it gets to a stage where it’s basically impossible to reason why the system is making any particular decision. The system collapses down under the weight of its own complexity, iteration speed grinds down to a crawl, and the product gets stuck in a highly sub-optimal state. In contrast, a realtime system likely needs more machinery to get started but is a lot easier to maintain and evolve over time. While there is some complexity in setting it up upfront but at least the complexity doesn’t compound over time.
What makes it worse is that a migration from an offline system to a more realtime system is often very tricky because of how different the paradigms are.
Conclusion
In this post, we examined the top seven reasons why so many companies are making their ML stacks be a lot more realtime. Many of these reasons likely apply to any ML systems that need to evolve based on the user’s behavior need (e.g., fraud, ranking, recommendations, pricing, etc.) — and if they do apply to your applications, you might want to proactively lean into realtime ML to future proof your stack as well.
here are many applications where the ML system doesn’t need to evolve with user behavior. For instance, many automatic speech recognition systems are relatively static in relation to user behaviors. Hence, the trend toward a more realtime stack is much weaker in such applications. ↩︎
When we hear about realtime ML, some people conjure up the image of continuous model retraining. However, while it can be valuable, in our experience, most top tech companies aren’t yet doing continuous model retraining yet. In other words, the ROI of continuous model retraining is much lower than that of realtime features and realtime model scoring. ↩︎