Realtime machine learning relies on models, and models are only as good as the data they are built upon. One of the biggest challenges in machine learning is keeping data up-to-date and accurate, and transforming it in a way that the model can ingest it. In most applications of realtime machine learning, there are several data sources that are aggregated to provide you with the data you need, complicating matters further. What’s more, different teams are responsible for different stages of the ML pipeline (Data scientists are responsible for surfacing data and building the models, Data engineers are responsible for ingesting and formatting the data so it can be used with the models, and ML Engineers are responsible for deploying the models to production), and the languages and types of data needed by each team can vary significantly, making it difficult for them to collaborate or share resources.
Over the last several years, top tech companies have started adopted feature stores to make it easier to manage these and other aspects of feature engineering. In this post, we’ll introduce feature stores and how they can help alleviate these pains, and more, to help you run a “well-oiled” realtime machine learning system.
Definitions
Before we jump into what a feature store is, let’s make sure we are all aware of some of the terminology we’ll be using to describe their merits…
Features
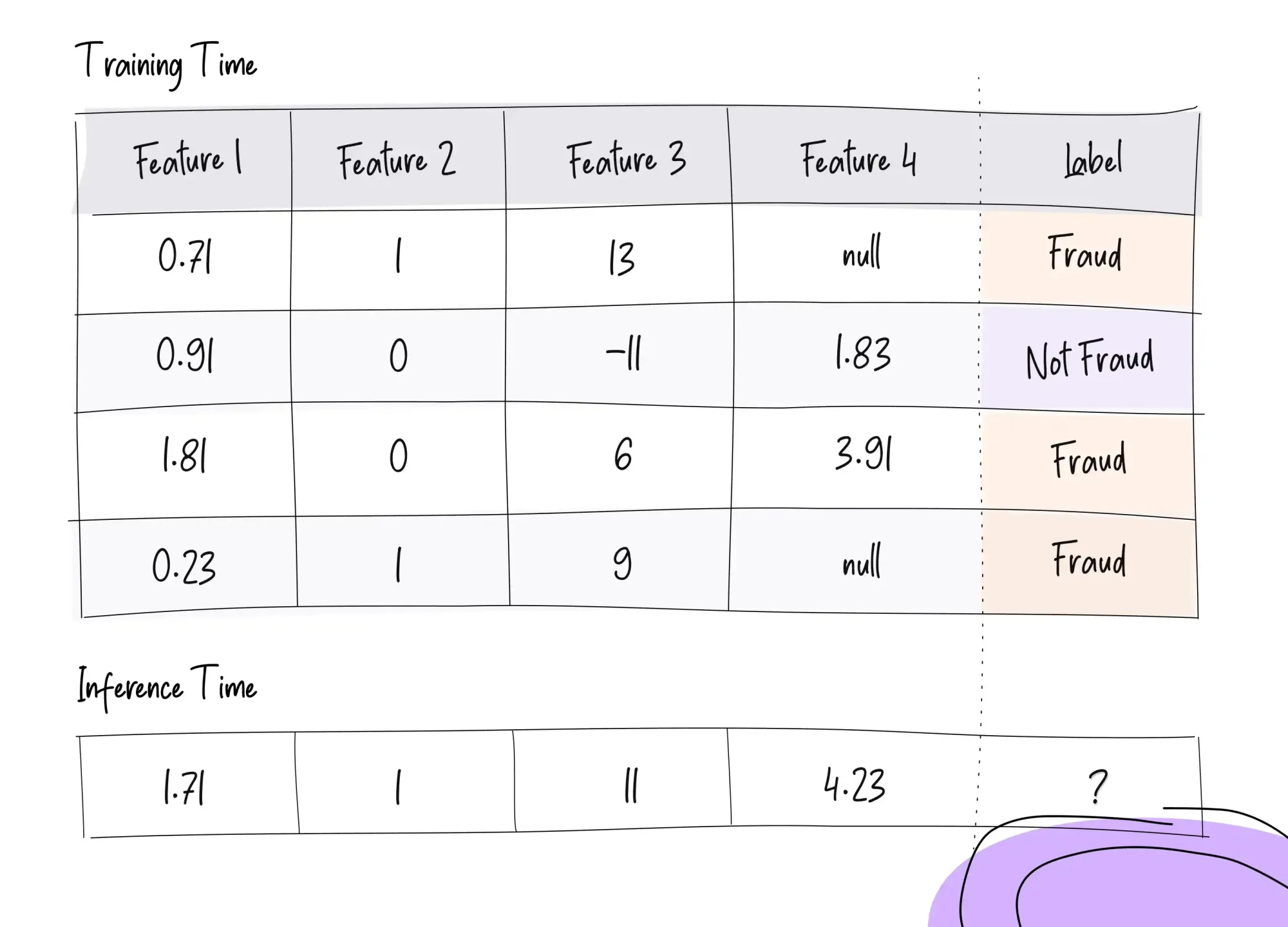
Features are essentially the data that is input into machine learning models, either to train them or to get predictions out of them, once they are trained. Features should be measurable attributes, like price, color, duration, or age, and the best features to use for your model are going to be the ones that most specifically relate to or identify your desired results (there is a whole field around this practice, called feature engineering). For example, if the model is trying to determine whether a transaction is fraudulent on a specific individual’s credit card, some of the features for that user’s ID will be more useful than others:
- A feature containing the person’s “height” will not be of much use
- A feature for that person’s “transaction frequency” could be relevant
- A feature containing their “max transaction amount” could be relevant
- A feature for that person’s “average transaction amount” could be relevant
- A feature for the “location” where they have recently made charges could be relevant
Feature Pipelines
As mentioned above, features need to be in a specific format to be useful to a model. For example, the data you receive from the fitness app the user connected to your platform may send you the start and stop times of the user’s workout, but you may need the workout duration for your model.
-
Feature pipelines are often created by Data Engineers to transform the data you receive into the features you need (and can perform much more complex transformations than in the example above, too).
-
Feature pipelines can also aggregate data from multiple sources (which may be coming in different formats or intervals), and validate that the data you are receiving makes sense, or if it should be removed from the dataset before processing (e.g., null values, or values that are outside of the range that makes sense for your feature, like a “shoe size” of 100).
Feature Stores
A feature store is a system that manages a collection of features for the models and is responsible for managing the full life cycle of a feature – from computing and storing to serving as needed. Here, we’ll highlight some of the benefits of using a feature store for your realtime machine learning system.
Online and Offline Stores
The requirements of feature serving are very different between online and offline modes. In online mode, when the user is waiting for the model to make a prediction live, latency matters a lot. And so the features that go into the model need to be retrieved very quickly, often in milliseconds.
But when training a model, features need to be generated for millions of data points at once - which can easily take minutes to hours. At this time, what matters is throughput - how quickly can millions of features be generated.
This is why feature storage/serving is often done via two parallel systems — one called online store and the other called offline store. Generally, you’ll have both an online feature store and an offline feature store, but part of the magic is that the feature pipelines used to populate the features can easily be directed to update both stores.
Having the same feature pipeline push data to both locations ensures data consistency, which allows for more accurate models, and fewer issues with miscommunications about the attributes of the features for the models your team is building and deploying.
Reusability and Collaboration
One of the points touched on above is that it takes several teams, working on different stages of the system to implement and maintain a realtime ML system. Especially for larger realtime systems with lots of moving parts, these teams can’t be checking in with one another for every move they make, but it does help to have some communication and standardization to keep the system going.
-
If one person needs to double-check the name or units of a feature, they don’t need to reach out to another team and wait for confirmation; having a feature store provides a centralized location for everyone to utilize and reference.
-
Having everything in a central location for everyone to use also means that each team doesn’t need to spend extra time developing their own features to work within their stage of the system.
The ability for different teams to reuse the same features also extends to the ability for different models to use the same features (some companies even publish how many times a feature has been reused!). All of the ways in which feature stores allow features to be shared and reused equate to increased efficiency and velocity.
Another added collaborative benefit of feature stores is that they enable a wider part of your team to reap the benefits of realtime machine learning. Machine learning is a complex topic and, with many systems, only the teams whose jobs it is to build or utilize the features and models have the capability to do so. With a feature store, users or applications can simply provide the ids for the entities (products, customers, etc.) they are interested in getting predictions for, and the feature store knows which features to pull for the model needed for the desired prediction. Having this ability to simply utilize the entity IDs also allows more people to contribute, either by adding new features, or by using a data-first operational ML platform to allow them to contribute to building models.
Data Consistency
The above sections alluded to the value of data consistency and the need for different teams to make sure that they are all using the same feature names and units; this is because it is important that the data training the model is in the same format as the data the model will be receiving once it is in production. Because everyone is working with, literally, the same features, there is less risk of someone building their piece of the puzzle using the wrong name or units (less risk, because, as we talk about in our Challenges of Building Realtime ML Pipelines post, sometimes properties like units change and this isn’t properly communicated).
Maintenance
Another awesome benefit to using feature stores is the metrics they keep on the features and models that use them. This means that it is easy to identify data drift, with statistical tests, to see:
- When the data that the model you’re using was trained on no longer aligns with the live data
- When your model that isn’t performing as well in production as expected, if you are alerted to drift soon after deployment
Debugging with a feature store is incredibly easy because you can quickly see information about when a feature is used and what models use it, rather than having to waste (a lot) time chasing educated guesses through your logs.
Point-In-Time Data
These metrics can also be incredibly useful when it comes to understanding how your data and the ways in which it is being used, in order to build better models in the future. It can be challenging to refer back to historical data with many ML systems, but historical data is useful for being able to do retros on trends that weren’t previously recognized and finding new patterns to look for in the future. Each data point in a given feature has a timestamp associated with it, meaning that your feature store can create “snapshots” of what your features looked like at any point in time. This can be helpful for debugging and better understanding the outcomes of your models and their predictions, as you perform retros on models to ensure they are working and to ensure your practices for building models are effective.
Lineage Tracking
The final way we’ll highlight the usefulness of the metrics feature stores contain is with lineage tracking. Having an understanding of how features and models are connected aids in general understanding of the data being used and what it might be used for in the future, but also helps with improving collaboration. Knowing which models are using which features allows the people working with and controlling the features in the feature store to be aware of what might be impacted if a feature were to be updated. This means that those making the updates can accurately communicate them to the relevant team members or teams, and avoid that type of miscommunication we mentioned in the Data Consistency section.
Wrapping Up
When used properly, feature stores can simplify many of the challenges of building and maintaining a realtime machine learning system. Feature stores in and of themselves have a good bit of complexity:
- Building a system that provides the appropriate architecture for online and offline use cases
- Writing statistical tests to detect drift
- Creating appropriate feature pipelines for the type of data you need
- Etc.
However, once you have an understanding of what it is you need from your feature store, the organization, collaboration, and metrics you receive from having implemented a feature store will remove many of the complexities of the greater realtime machine learning system, and make it more approachable to a wider section of your company (which could also help more people empathize with the value realtime machine learning provides at your company and give you justification for devoting more resources to it).
Feature stores are also one of the core structures of a Feature Engineering Platform like Fennel, which builds upon the functionalities of a feature store to make working with realtime ML even easier and faster, by fully managing your cloud resources, simplifying the process to ingest and transform the data you want to use, and providing built-in unit and integration testing. Fennel creates the fastest path to authoring and serving production-grade realtime features for recommendations, fraud detection, search, and more.