Introduction
Fraud detection is critical in keeping remediating fraud and services safe and functional. First and foremost, it helps to protect businesses and individuals from financial loss. By identifying potential instances of fraud, companies can take steps to prevent fraudulent activity from occurring, which can save them a significant amount of money. Fraud detection also saves users a lot of headaches and instills trust in them when they know these protections are in place.
There is a wide variety of applications under the broader umbrella of fraud/risk detection — credit card transaction fraud, payment fraud, identity fraud, account takeover, etc. All of these types of fraud or risk can be broadly categorized into two types — first-party fraud (i.e., fraudulent users trying to trick a bank) or third-party fraud (i.e., a bad actor who is trying to compromise the account of a legitimate user). Most of these applications have a similar structure when it comes to ML and feature engineering, which we will explore in this post. First, we will briefly describe how the modeling problem is formulated and how the labels are obtained. And finally, we will do a deep dive into feature engineering for fraud.
Modeling
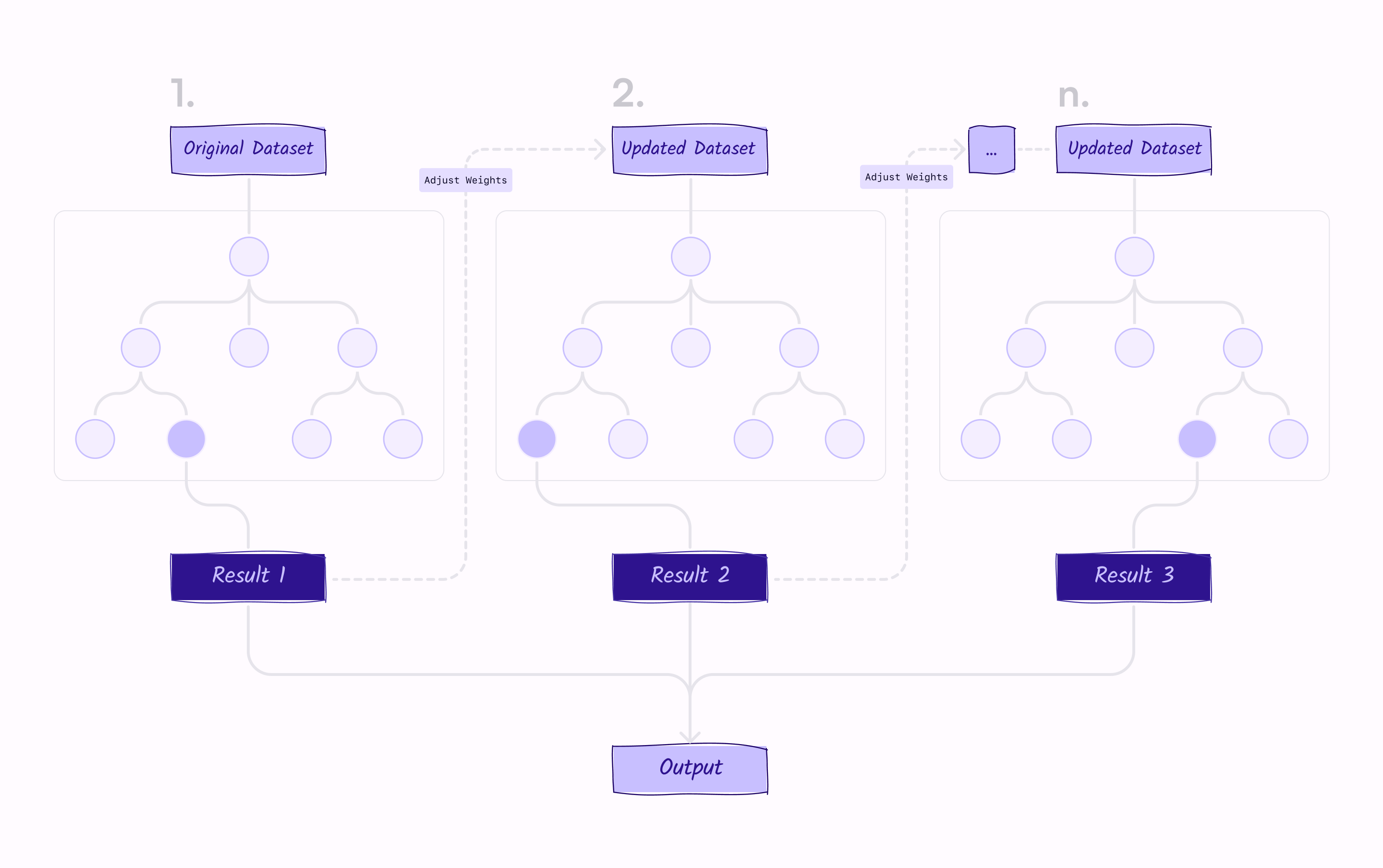
The fraud detection problem is often modeled as a supervised learning-based binary classification, and Gradient Boosting Decision Trees (GBDTs) are often used as the model. GBDTs work by training a service of decision trees on the data, where each tree is built to correct the mistakes made by the previous trees in the sequence.
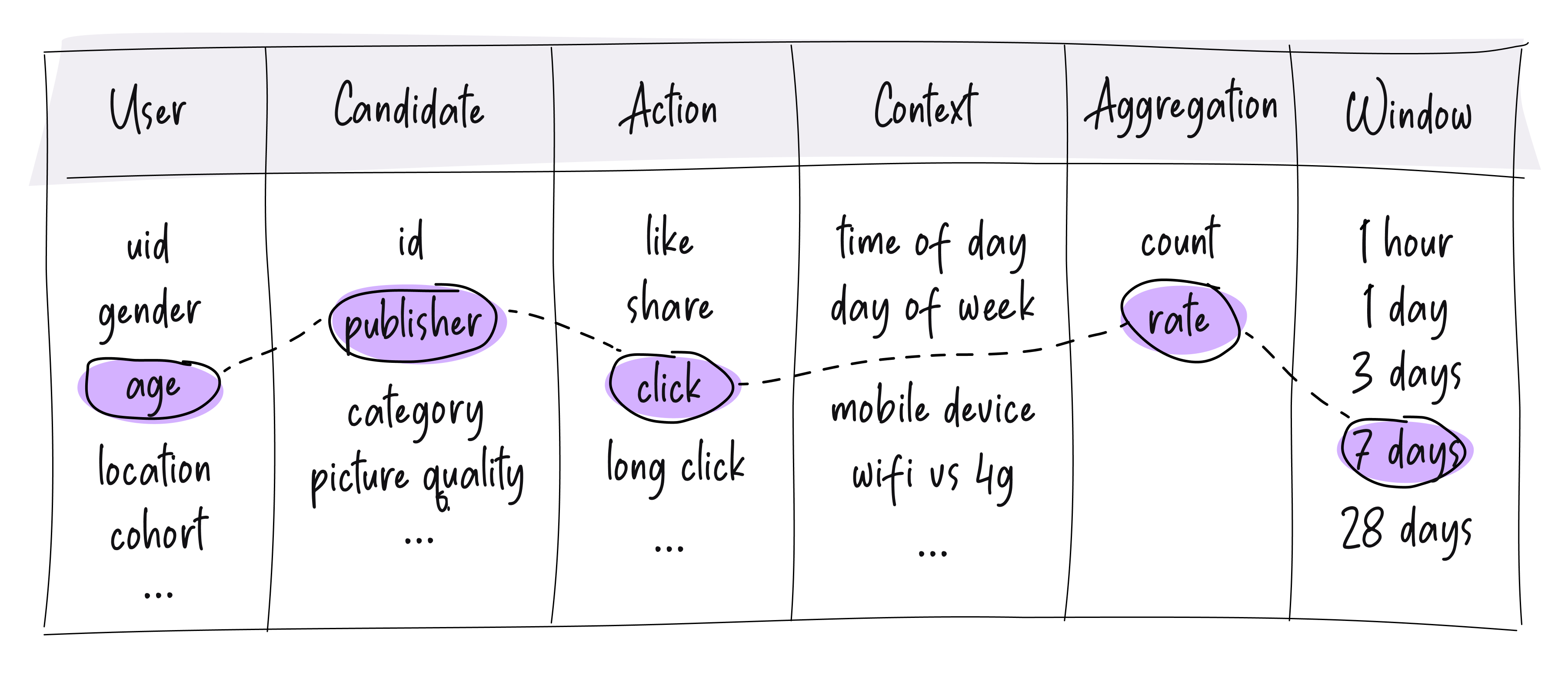
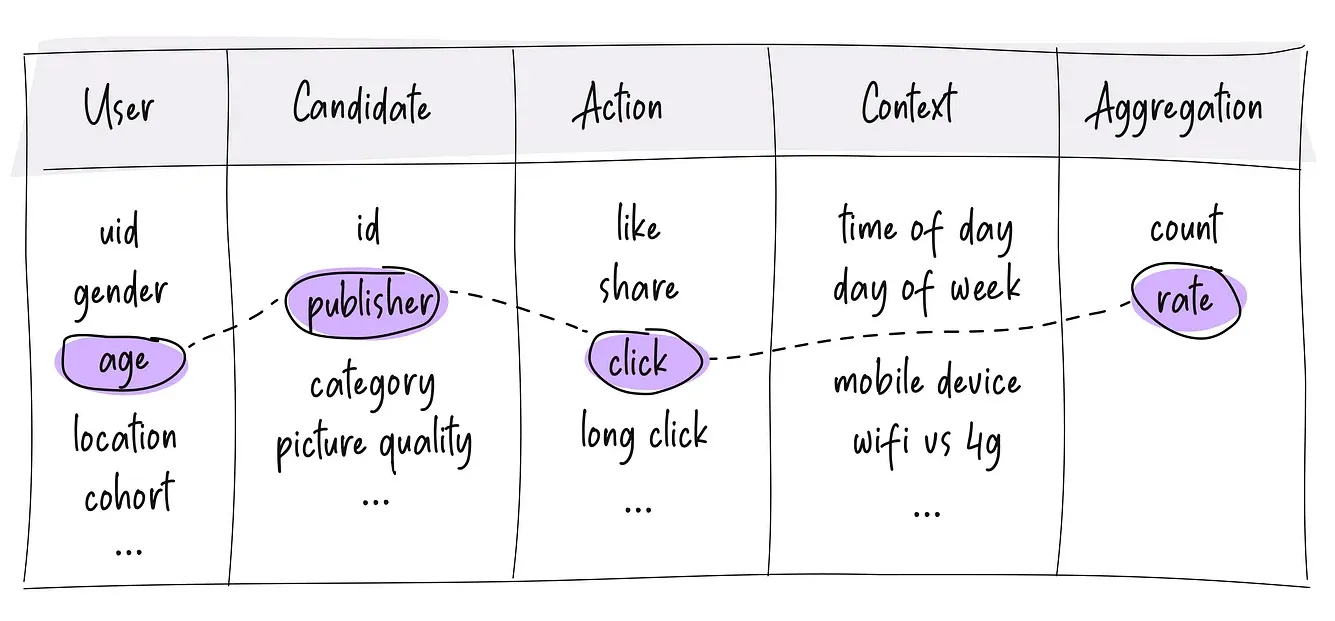
In the case of fraud detection, the features input into the GBDTs might include information about the transaction, the customer involved, and any other relevant financial or behavioral data, and whether training data includes labels that indicate if a transaction is fraudulent or not.
The GBDT algorithm uses this information to identify patterns and relationships, even complex non-linear relationships, that are indicative of fraudulent activity. By training the model on a large dataset of known fraudulent and non-fraudulent transactions, the GBDT algorithm can learn to make highly accurate predictions about the likelihood of a given transaction being fraudulent.
Fraud detection often involves working with large and highly unbalanced datasets, where the number of fraudulent transactions is relatively small compared to the number of non-fraudulent transactions. This can make it difficult to identify the features that are most relevant and useful for training the model. To mitigate this, there are a few approaches:
- Oversampling the fraudulent transactions or undersampling the legitimate transactions – this can balance out the dataset, but can also lead the model to believe that fraud is more frequent than it is.
- Changing the metrics used to evaluate the model – you can use metrics like precision, rather than accuracy, or use the F1 score to evaluate how well the model is performing.
- Using algorithms like ensemble methods or cost-sensitive learning – Both of these algorithms can help improve the performance of the machine learning model on the minority class. GBDT (which itself is an ensemble) is a great algorithm for fraud detection because it is powerful and flexible, and relatively easy to use and interpret, but some other ensemble methods are particularly effective at handling imbalanced datasets, and cost-sensitive learning is particularly adept at considering the costs associated with false positives and false negatives.
Labels
Since the problem is formulated as supervised learning, ground truth labels are needed to train the model — in this case, whether transactions as fraudulent or non-fraudulent.
In some problems, e.g., credit card transaction fraud, if a transaction was incorrectly classified as non-fraudulent and permitted to happen, the end user may dispute the charge. That can serve as good quality labels. But in general, obtaining high-quality labels in a timely fashion is a huge problem for fraud detection, unlike recommendation systems where what the user clicked on can easily serve as good-quality labels.
As a result, typically, humans often need to be involved to manually provide the ground truth labels along with a bunch of automated augmentation/correction mechanisms.
Another challenge with labels is that there is a delay in receiving labels. There is typically a 2-3 week delay in processing fraudulent activity on an account. In some problems, like account takeovers, malicious actors may wait months before starting to use the accounts to say post spam or conduct transactions. In such cases, the system may not find out the correct label of a decision for account fraud prediction for many months. In general, it can take around 6 months to get 95% of all labels which means models have to be trained on several months old data at any point.
Feature Engineering
In order to create effective features for fraud detection, it is necessary to understand the underlying data and the problem that the model is trying to solve (first or third-party fraud, as well as the types of fraud therein). This often involves a combination of domain expertise, data exploration, and experimentation to identify the most relevant and informative features to use as input (often accomplished through exploratory data analysis, or “EDA”). Once these features have been identified, they may need to be transformed or combined in order to make them more useful for training a machine learning model (also included in EDA). This process of feature engineering is crucial for achieving good performance in fraud detection and other machine learning tasks.
One of the challenges with feature engineering for fraud in particular is that, like with labels, much of the most useful features need to be handwritten. There are some features that can be used from the raw data, but, more often than not, the most useful features are ones that combine several different pieces of data, like the amount and the location and time of day (e.g., someone is likely to spend more money on dinner in a high cost-of-living area than they are to spend at a coffee shop in a low cost-of-living area) and/or splitting the values for a specific piece of data (like splitting the date from the time or the dollars from the cents of a transaction amount).
Some of the most common patterns of features for fraud detection include:
- Affinity features built on top of rolling counter-based features — how many times an event of some kind happened in rolling windows (e.g., how many times a user has made an ATM withdrawal in this city in the last 6 months or the average transaction amount for a user with a particular credit card).
- Velocity features — how quickly events happen (e.g., the ratio of the purchases the user made in the last hour to the average number of transactions they made per hour in the last 30 days). These are also ratios of some counters, even though the focus is on capturing the velocity of the actions taken vs. the affinity between two entities.
- Reputation features — some “reputation” score for various things like the email domain of the user, the IP address the activity is coming from, the vendor the purchase was made from, etc. Some of these are, again, using counters of past behavior.
- External API-based features — e.g., the credit score of the user or location of an IP, etc.
- Relatively static profile features — e.g., the zip code from which the request originated or the age of the user’s account, etc.
As mentioned above, determining which of these features is most useful involves a lot of industry knowledge and experimentation (since the normal log and wait process would require you to wait months for results, due to the nature of the data being received and the rate a which it is received). When doing experimentation via exploratory data analysis (EDA), the engineer uses different statistics and visualizations of the data to find the best data points and combinations by looking for patterns, anomalies, and relationships between data (which can also inform the engineer that only one piece of data from the relationship needs to be used).
Note that even though fraud models are trained on very old training data, realtime ML still gives you a massive leg up in fraud detection because of its adeptness with long-tail, as referenced in this post.
Enjoying the article?
Join 1000+ others on our newsletter mailing list and get content direct to your inbox!
Unique Feature Engineering Challenges
Feature engineering for fraud detection can be challenging for a number of reasons. As was mentioned before, fraud is a complex and dynamic problem that can take many different forms, which makes it difficult to identify the specific patterns and relationships that are indicative of fraudulent activity.
Fraud detection often requires working with sensitive financial data, which may have strict privacy and security requirements. This can make it difficult to obtain the data that is needed for feature engineering and can also limit the types of transformations and manipulations that can be performed on the data. When working with sensitive data, your best chances of success are to:
- Ensure data is properly secured – to protect against unauthorized access, implement security measures such as encryption, access controls, and monitoring.
- Consider which data is actually necessary – during the feature engineering stage, using tactics such as exploratory data analysis (EDA) helps you to see if any of the features in consideration have relationships with others, which can allow you to select the less sensitive metric for the model that will be put into production.
- Anonymize the data as much as possible – your use of sensitive data is more likely to be allowed to continue if proper protections are put in place. The first layer of ensuring this is making sure only the people who should have access to the data do, as mentioned in the first bullet. It is also a good practice to anonymize data within your system, in case of situations such as compromised credentials being utilized by bad actors.
Another challenge is that, as previously mentioned, labels are often delayed, so training data consists of very old examples (sometimes several months old). This means that, if you were to employ the popular practice of logging and waiting, you would need to wait months to test a new feature. This is why a practice such as EDA is often used. Another “issue” with labels being delayed is that point-in-time data feature reconstruction needs to cover a long window (often times a year) to get the necessary data volume. This also increases the risk of feature code changing, which further necessitates immutability or versioning of features to prevent confusion and ensure that you’re working with the correct data, in the correct format.
Earlier, we mentioned that it is especially common to create features for fraud detection models by combining or splitting the features you receive from the raw data. This often means that you need more data sources to get enough data of the types you need, which increases the need to hit external APIs. Sometimes, this comes in the form of batched data dumps (like the credit scores for a large number of people as of a certain date) that need to be “merged” with live requests (like to a credit bureau) in a lambda-like architecture. With live requests, it is also important to consider the latency constraints mandated by the system or use case. In most cases with fraud detection, it is very sensitive to lag, since a bad actor can do a lot of damage in even a few seconds. This means that features must be only a few seconds old, if that. In addition, serving latencies of the models using those features need to be incredibly low; often, a serving latency of around 200ms end-to-end (including feature extraction and model scoring) is required to make a decision as to whether a transaction is fraud in an acceptable amount of time.
Another reason that working with external APIs (e.g., hitting credit bureau APIs for credit scores) is hard is that it can be difficult to create correct point-in-time values; since the data is external, you don’t always have easy access to historical data or the details you need from it, meaning you need to ensure you record all of the right information when you first access the data. For example, we mentioned that the IP address is a feature that can be used to predict fraud; one issue with this is that the location of an IP changes over time, so you need to know the location of the IP at the time of training, which mandates careful managing of the data obtained from external APIs, so that you have the details you need when you need them in the future.
Final Thoughts
Feature engineering is a complex artform, and the precision and thoughtfulness that needs to go into it when working with sensitive data and high stakes, like in the case of fraud detection, further complicates its planning and implementation. While there are a good number of things to account for when performing feature engineering for fraud detection, this article helps to highlight many of the challenges, technologies, and strategies that can be employed throughout this process to give you a leg up when going through the process.
If you would like to see an example of how these strategies can be employed, NVIDIA did an awesome writeup of the winning solution from Kaggle’s IEEE CIS Fraud Detection competition.