The way ML features are typically written for NLP, vision, and some other domains is very different from the way they are written for recommendation systems. In this series, we’ll examine the most common ways of engineering features for recommendation systems.
In the first part (i.e., this post), we will look at counter and rate-based features and a few best practices related to writing them. In the second part, we will look at a few more techniques and best practices for writing good counter/rate based features. And in the third and final part, we will look at more advanced kinds of features that work well for large neural networks. But first, let’s address a beginner FAQ right away.
FAQ: I thought recommendation systems were all about collaborative filtering, which doesn’t need ML features. So, what features are we talking about here?
Answer: as described in this post, recommendation systems have many distinct stages. Collaborative filtering is one of the many algorithms for powering (a subset of) retrieval. Irrespective of the choice of retrieval algorithms, candidates obtained from retrieval still need to be ranked by another ML model — often called the ranking model. This post is about the features used in ranking ML models.
Okay, with that out of the way, let’s talk about counter/rate based features that are the bedrock of feature engineering for recommendation systems.
What are counter and rate-based features?
The golden principle of any modern personalization system (including recommendations) is that learning directly from people’s behaviors works a lot better than learning from their stated preferences. And one of the best and simplest ways of featurizing behavioral patterns is through counter and rate-based features.
A counter feature, well, is just that — a feature that counts something, typically some sort of user behavior. For instance, the number of times a user has clicked a product of some category encodes their behavioral affinity towards that category and is a counter feature.
A rate feature is a near cousin of counter feature — it’s simply the ratio of two related counters. As an example, in the above example of user-category affinity, a feature that may capture the user behavior even better is the fraction of times the user clicks on a product of some category upon viewing it.
Whenever I start on ANY recommendation problem, I always start with a few counter / rate features along with a basic GBDT model. This baseline of counter/rate features with GBDT takes a model very, very far. In fact, these features are responsible for a large part of model performance for even the most sophisticated ranking/recommendation systems in FAANG and other top tech companies.
Okay, so hopefully, you’re convinced that you should write counter / rate based features. Let’s now examine some techniques and best practices for using them.
1. Choosing the appropriate splits
Typically you’d want to write lots of counter features corresponding to various kinds of splits. Here is an example of related but different counter features for a social media recommendation system:
- Click rate of user on items written by a particular author - this encodes user’s affinity towards content from this author.
- Click rate of all male users of a certain age group on items written by a particular author — this encodes the preferences of a whole demographic towards the content from this author.
- Click rate of all user on items written by authors having received verified badge — encodes the idea that verified users may (or may not) have higher quality content and that their content gets a different kind of engagement.
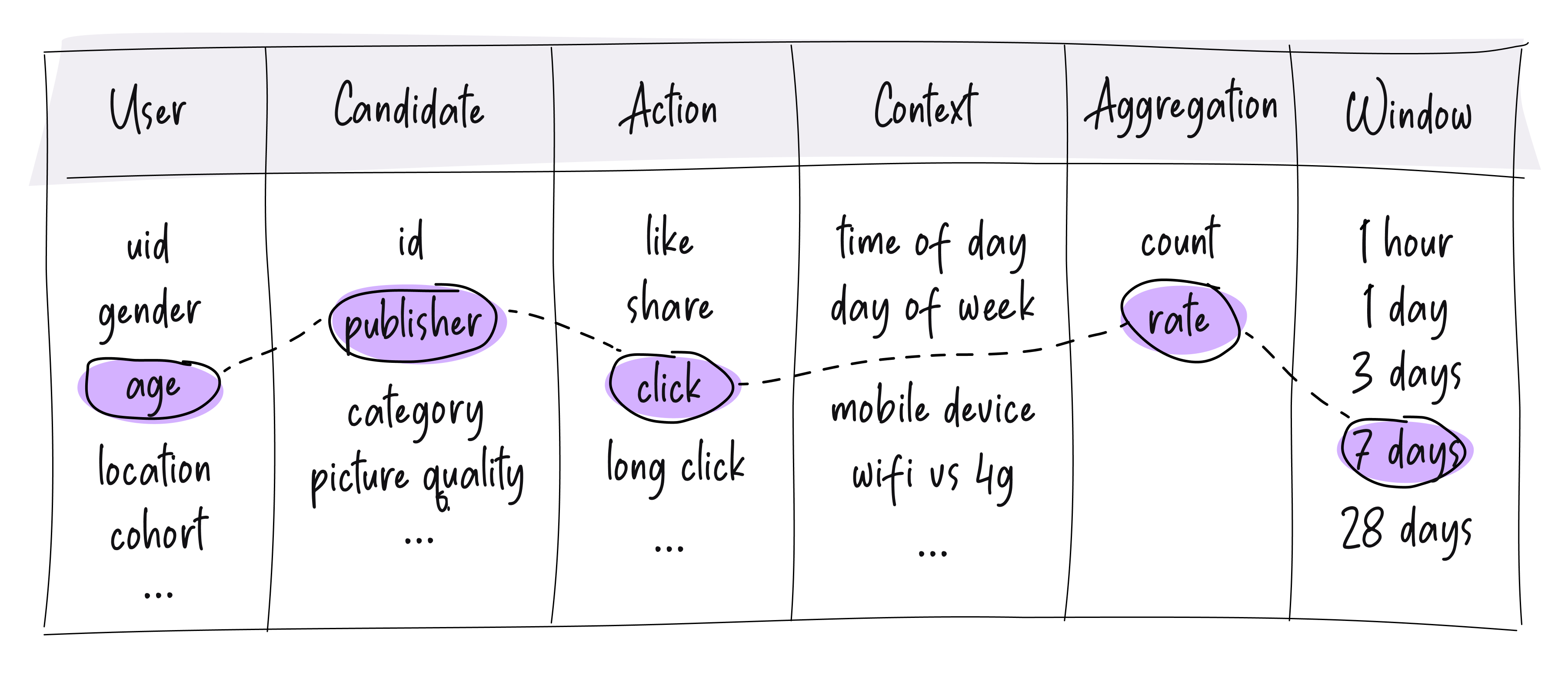
These all look somewhat similar but in fact, are encoding very different product intuitions. Good counter/rate based feature engineering comes down to just capturing as many useful splits as you can that encode useful product intuition. One useful tool to visualize this is to imagine a table like this:
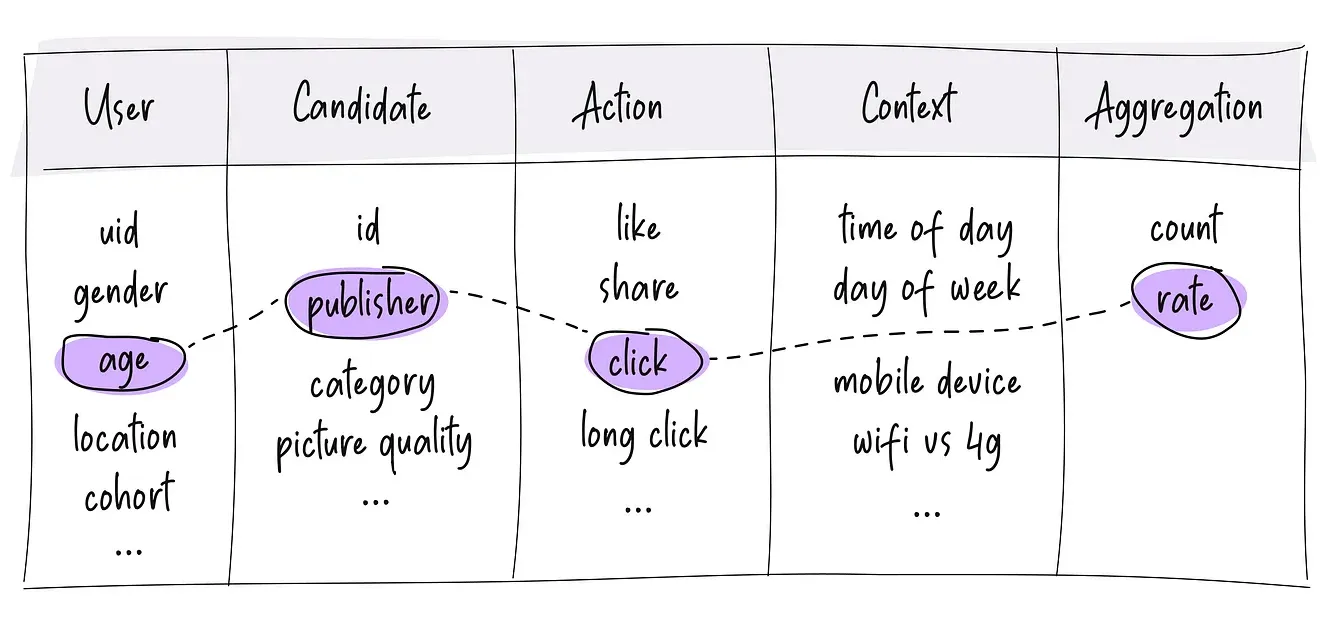
You can pick any combination of the properties. For example, maybe you pick age from the user column and publisher from the candidate column, pick click from the action column, pick nothing from the context column and build a rate feature out of it, which will represent — the click rate of users of this age group on content created by this publisher. While not all combinations are going to be useful, many will be, and it is often worth building at least a couple dozen of these combinations as features.
2. But don’t make features too sparse
While you should choose any good splits, you should also be careful about not choosing splits that are too sparse. For instance, if one of your split is the click rate of user on content from a publisher on a given topic between 11am-12 noon, most likely almost all the splits are empty, and this feature is too sparse. Super sparse features like this don’t help the model much [1] and in fact, come at a huge computational/storage cost. How much sparsity is too much is hard to spell out, but my rule of thumb is to not have O(N^2) splits where N is the number of large-volume entities. For instance, a feature with (# of user, # of products) is potentially fine since the number of products in most e-commerce engines is small (though even this feature might not work at Amazon scale). A similar feature with (# of user, # of authors) is probably fine in the media world. But feature with (# of user, # of posts) might be too sparse even at a smaller scale.
3. Don’t forget to encode context
Most users have different behaviors based on their own context. For instance, they may be more interested in short byte sized headlines in mornings and longer-form content later in the evening. Or even more dynamic things like how much time they have already spent on your app since morning may affect their behavior.
These contextual signals are very powerful for model to make sense of the user behavior and make a huge difference in the quality. But the right way to encode them is once again via counter/rate features. So in addition to throwing the time of the day as a categorial feature, you might also want to add a feature that measures the user activity (say CTR) of user across all content at this time of the day.
Context features don’t have to be limited to capturing the preferences of a single user. They can also be used to encode broad preferences across many users. For instance, one powerful feature for any video streaming recommendation engine is — CTR of all users who are on WIFI on any video. This feature captures the idea that users who are on WIFI (vs, say mobile data) are much more likely to watch full videos.
4. Dynamically match users and candidates
In the above example of time of day CTR, should we create one feature per hour of the day? For instance, what is the CTR of the user between 12-1am, 1-2am, ….10-11pm, 11-12am? A much smarter idea is to only throw in one feature, i.e., CTR of the user at the current time of the day. That is, if the feature is evaluated at 5pm, use the user CTR between 5-6pm and if the same feature is evaluated at 8am, use the user CTR between 8-9am.
In fact, this idea is pretty universal when writing counter based features and is one area where beginners get stuck. As another example, say we want to create a counter feature capturing the user’s affinity towards the author of a post. We roughly know that we want to capture the CTR of this user on the post authors. But there are thousands of authors in the system — should we create thousands of features, one for each author?
Once again, this idea of a dynamic match comes to the rescue. The feature as evaluated on (user, post) will be defined as follows: what is the CTR of the user on the content written by the author of this post. And so the same feature will lookup the user’s CTR on different authors for different candidate posts. [2]
Conclusion
Unlike many other kinds of ML, most of the feature engineering for any recommendation or personalization system is based on counter or rate features. In this post, we reviewed some techniques and the best practices of encoding useful signals as counter and rate features. In the second part of this series published here, we will discuss a few more techniques for encoding counter / rate features. And in the third part of series, we will discuss how feature engineering is done for more advanced neural network-based recommendation systems — stay tuned
These super sparse features can be useful if you’re training a large deep neural network with lots of data. But they aren’t useful for regular-sized data with GBDTs. ↩︎
One implication of this is that there is a difference between the quantities that you pre-aggregate and the quantities that become features. In this example, you precompute CTR for all (user, author) pairs, but the actual feature has some more logic that determines which of these it is going to look up. ↩︎