While the implications of machine learning and data science can have a tremendous impact on society, failing to use the right feature engineering techniques can often lead to machine learning models not performing efficiently and giving sub-par results.
Artificial intelligence has long been a topic that fascinates the masses, and more and more industries are employing and talking about their use of machine learning. We have seen fascinating applications of Dall-E where once we give a description of what we want, and it returns an image according to our description. Other technologies involve using machine learning to determine the optimum sound levels that are given to listeners based on their genre preference. There are other interesting applications, especially in self-driving industries, that rely on machine learning models for predictions.
One of the biggest differentiators in how effective these technologies are is whether the creators are using the right feature engineering technologies; after all, it is the features that are fed to the models that determine their performance. For example, trying to determine whether a person might develop heart disease or not would sometimes be determined by just weight alone, or other factors may be required to make an accurate prediction. Failing to give these features to our model might make them not determine the driving factor behind heart disease. To make things more interesting, feature engineering can also determine other factors that were initially thought to not be that useful by humans to make predictions. Therefore, we see automation coming to light in a large number of these industries.
Now that we have seen that features are some of the important determining factors in our model performance, we will now explore some ways in which we can use these feature engineering techniques to improve the accuracy of our models. It is to be noted that accuracy is a metric that we take for classification problems, while error is a metric that we take for regression tasks. In this article, we will go ahead and look at various feature engineering techniques that are usually performed before giving the data to machine learning models for predictions.
Most Essential Feature Engineering Techniques
We will be taking a look at a list of all the feature engineering techniques that are being used mostly by data scientists and machine learning engineers to complete a wide variety of data-related tasks and provide value to the business.
Imputation
We tend to see large volumes of data present in various companies that can be used for machine learning. It is all about giving this data to our models before getting predictions from them so that they learn these essential patterns. However, there is a lot more complexity involved when it comes to getting those predictions.
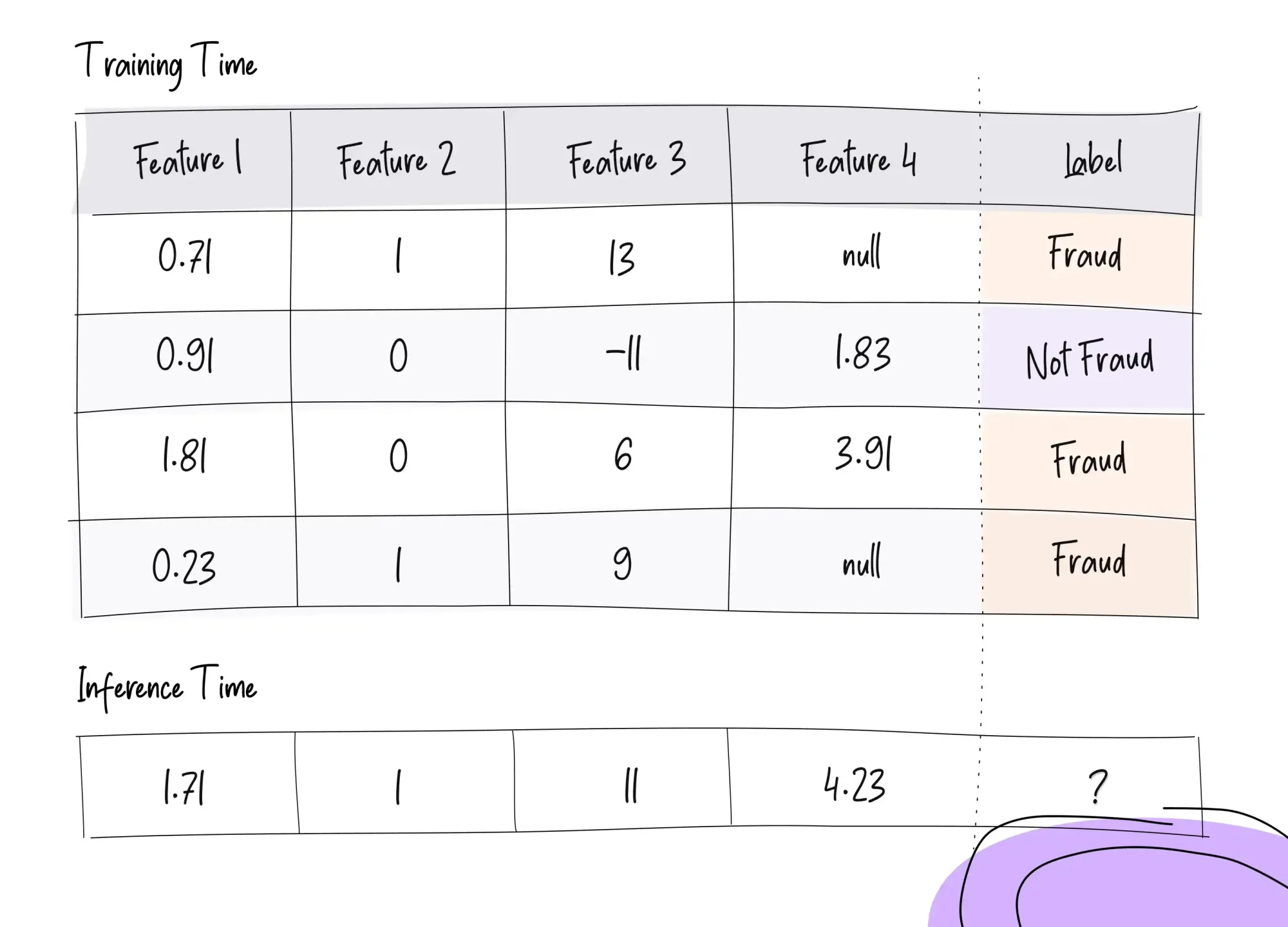
Real-world data that is often given to machine learning models contain missing values in a wide list of features. There should be methods used to fill in the missing values. If not done, the models would not be able to generate predictions in the first place. Therefore, steps should be taken to ensure that there are no missing values.
It is to be noted that if we were to remove all the missing features, we would have almost no data left. After all, there are large volumes of data that are readily available but with missing values. How do we ensure that we do not lose this essential information that would be given to ML models?
We would be able to use the feature engineering technique of imputation. It is a method where we take the overall mean for each individual feature and fill in those values that are missing with this data. In other words, we are just replacing those missing values from features with the average or mean value of the features, respectively. In this way, we are making sure that the essential information is not lost in the process, along with giving the ML model the right data, which can help it improve its predictions.
Scaling
Scaling is an operation where we take data that does not have missing values (or it did initially, but they were removed with imputation) and perform the operation of converting the given data so that each and every feature is of a similar scale. In other words, we are just adjusting the features in the data and ensuring that there are not too high or too low values that can impact ML model predictions.
To put things in context, consider the case of predicting the price of a mobile phone. Features that we consider are the total storage capacity and the display size. We know that the storage capacity is measured in either GB or TB (if it is extremely large). If we are living in the US, we would be measuring the price of the phone in $ (dollars). On the other hand, the display size is measured in inches or centimeters. If we were to consider these two features, we tend to see that they cannot be compared as they are measured in different units. This would lead the ML models to assume that one feature is significantly different from the other due to scale. However, this is not true in real life.
Therefore, scaling is an operation that ensures that features are of similar scale before giving them to ML models for prediction.
Enjoying the article?
Join 1000+ others on our newsletter mailing list and get content direct to your inbox!
Outlier Handling
Outliers in the data can make or break ML models put into production. What are outliers? Well, they are the data points that have extremely higher or lower values compared to the other values in all the features. These values can often make the models assume that they are important and sway them into giving predictions that are mostly inaccurate, leading to lower model performance.
These outliers can oftentimes not be noticed, especially if we fail to consider and acknowledge their presence in the data science industry.
Consider, for example, that we are trying to predict whether a person would be defaulting on a loan or not. One of the strong indicators that help the machine learning model to determine this would be the salaries of applicants. It is to be noted that not all the salaries given are accurate and there might be extremely high or low figures sometimes provided. If we were to just feed this information to the models, it would wrongly assume that having extremely high values of salaries can sometimes lead to default or vice versa. Therefore, the accuracy of the models in predicting whether a person would be defaulting on a loan is minimized.
It is important to remove these outliers from our data before feeding them to our ML models for prediction.
Creating New Features
While creating new features can often lead to models performing well, it is important to have domain knowledge, especially if we are working in industries such as banking, retail, and manufacturing, before adding them to our data. The kind of features that are often being fed to our models determine how well they are going to be performing in real time once they are deployed. During the training phase, therefore, care must be taken to generate new features based on the existing ones so that the model can better decipher the output classes if it is a classification problem or better match the values to be closer to the actuals in the case of regression.
Consider the case of determining whether a person is going to apply for health insurance depending on his/her health condition. If we are not given BMI information and were only given features such as weight and height, we might be missing one important and interesting component when we are giving this data to our model. BMI can be one of the factors that can influence whether a person might be enrolled in health insurance. Based on our domain knowledge that BMI can be measured with the weight and height of a person, we ensure that this vital piece of information is created before training our model.
We have now seen how important it can be to create new features based on existing features. One of the ways in which we can build this skill is to learn various factors that can have a strong impact on the outcome of the algorithms. It is also a good idea to apply for data scientist roles for which you have good domain expertise so that you can create these drivers that influence the models quite strongly.
Encoding Features
We have earlier discussed that the kind of features that are given to models oftentimes influence their performance in realtime. However, it is also true that the type of our features has an equal impact as well when it comes to predictions. Whenever we are dealing with data, it consists of three categories: quantitative, ordinal, and categorical features.
Quantitative features are the ones that require minimal procession. We just scale those features before giving them to our models for training.
Ordinal features are the ones that are quite tricky to understand but can have a significant impact on the project. If we were looking at the top 3 finishers in 100 meters race throughout Olympic history, the place of the contestant is an important factor in determining whether a player is going to win in the next Olympics. In order to do that, we would have to consider the contestant’s position as an ordinal feature, and we should give order in the form of numbers for our models.
If we have categorical features, on the other hand, we might have to give equal importance to all the categories without giving precedence. An interesting example would be to consider various locations for determining household income. In order to do this, giving precedence and order to the California region compared to that of Massachusetts would introduce bias to our models. Therefore, categorical encoding is followed to ensure that they are treated well with machine learning.
Applying Log Transformation
In real life, we often find a lot of information that is heavily right or left-skewed. Take, for example, the salary information from a demographic region. In this case, we find that most of the salaries are heavily concentrated in a particular region, while there are just a few salaries that are significantly higher than the rest. If we were to introduce this feature to our ML model, it would automatically be difficult for it to interpret as there is a heavy spread and variance in the data due to just a few salaries having too high or too low values.
In order to counter this scenario, the best method that is often used by many practitioners is to perform log transformation. As a result, the spread in the data due to having large values or low values is minimized and gives equal ground for the algorithms to make predictions much more easily. Therefore, this is one feature engineering technique that is followed for variables (or features) that have a heavy skew in their data.
Final Thoughts
All in all, feature engineering is one of the important aspects when it comes to applying machine learning in various applications. Some of the most essential feature engineering techniques are scaling, outlier handling, creating new features, encoding features, and applying log transformation.
While the type of feature engineering that we select depends on the type of dataset we are using, choosing the right one can improve machine learning model predictions to a large extent.