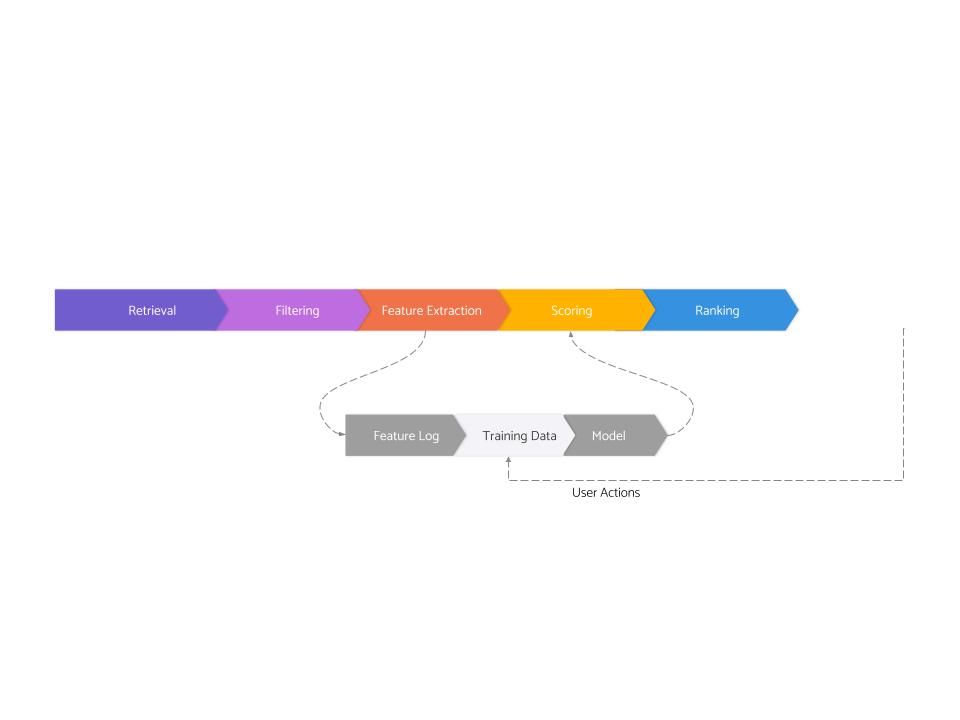
This is the second post in a series about the architecture of real-world recommendation systems developed at FAANG and other top tech companies. The previous post gave a broad overview of the serving side, and this post will provide a broad overview of the training side of recommendation systems. In particular, we will go through feature logging and training data generation — the next two stages out of the total 8 stages. And the final stage of modeling has enough complexity that we will tackle it in a dedicated post later.
So overall, this is where we are in this series:
- Retrieval (covered in part 1)
- Filtering (covered in part 1)
- Feature Extraction (covered in part 1)
- Scoring (covered in part 1)
- Ranking (covered in part 1)
- Feature Logging (this post)
- Training Data Generation (this post)
- Model Training (to be covered in the next post)

6. Feature Logging
As described in this post, information leakage is a really fundamental problem in any ranking / recommendation system. If not fixed, this may lead to the model effectively learning “noise” and failing to make good recommendations. In particular, temporal leakage of information from the future due to incorrect features is a huge problem.
As that post mentions, there are two ways of solving this temporal leakage — feature logging or reconstructing the features later. Between these two options, FAANG and other internet-scale companies, by and large, take the former approach and just log their features at the serving time. This choice works for them for two reasons:
- They have enough traffic that logging features for a week, even at a small sampling rate, generates hundreds of millions of data points for training, enough data to train reasonably powerful neural networks.
- They have such large-scale and complicated data models that reconstructing all their features at prediction time is impossibly hard.
However, both of these reasons may reverse at a very small scale, and there may be companies out there where reconstructing features may make sense. There is no free lunch, however, and this approach of reconstruction isn’t without its own downsides — it comes with huge complexity and operational overhead, which incidentally also does not work for small companies.
My rule of thumb is that as long as you can generate enough training data by logging at 100% sampling rate within 2 weeks or so, feature logging is a better & simpler approach. But if it takes substantially more than 2 weeks to generate enough training data, reconstruction should be seriously considered.
How much training data is enough, you ask. Well, that depends on the number & nature of the features you have and the specific algorithm/model you want to use. But as a super rough rule of thumb, tens of thousands of examples are sufficient for a linear model (say logistic regression), few hundred thousand to a few million examples are good for GBDTs, and tens of millions or more is where neural networks begin to work. And unless you know what you’re doing, you should only limit yourself to logistic regression, GBDTs, and some simple neural networks.
Note that if you choose to go with the feature logging, you’d need to support the logging of experimental features — features that are not part of the production models yet but still need to be logged for a week or two before they can be used in the next iteration of the model training. This is pretty essential and needs to be a part of any real-world recommendation system.
Finally, it is often desirable to log a fraction of features with a lot of metadata for all the candidates, not with the goal of using that to train the models but to provide observability into the whole recommendation funnel.
7. Training Data
Once features are logged, training data needs to be generated. Training data for any ML model consists of a series of examples — each example describes one particular thing (e.g., the content shown to the user at time 7:03am) using a few features and also contains a “correct” label for that example.
In many kinds of machine learning, the correct label can be produced by any human. For instance, given an image, anyone can label it as “contains a car” or “does not contain a car” — indeed, that’s what the captcha system is based on.
But personalized recommendations are different — given a particular product, was recommending it to a user the right decision in hindsight? Well, who is to say except the user themselves? And alas, we can almost certainly never ask them, at least not at scale. So we have no choice but to infer the correct label based on their actions — e.g., did they end up clicking on the content that was shown to them? [If you think relying on clicks is a bad idea, put a pin on that thought because we’d talk more about it in the Modeling stage below]
And so this is how training data is formulated for recommendation problems in FAANG and other top tech companies — feature data is logged when predictions are made, and it is “joined” later with a binary label — 1 if the user took the specific action on the recommendation that was shown to them and 0 otherwise.
To facilitate a join, some sort of ID is generated at the recommended time and attached with recommendations as they are sent to the web/phone client. When a user takes the desired action on them, the client sends the same ID back. In the background, features are logged with that ID. This way, joining between the features and actions is facilitated using that ID.
Since actions are logged from the client side, they may be buffered /batched at multiple places (e.g., logging each click as it happens on the phone may be bad for the battery). As a result, actions sometime arrive at the server several hours late. In fact, in some cases, they may even arrive a few days late — e.g., a user saw their recommendation but then left with a tab open and came back 2 days later to purchase the product. Or in an extreme case, an ad was shown to a user after which they started doing research about the product, but they finally made the purchase two weeks later – ideally, the ad recommendation system will label that particular ad to be successful despite a two-week delay.
There are a few things worth calling out here:
- Since actions are needed to produce training data, we can only ever include those things that the user got a chance to interact with. In other words, if our serving system evaluated four hundred candidates and finally returned only the top 20 to user, the remaining 380 can not be a part of the training data.
- Usually, some sort of client-side trickery is needed to fire / record events for training data carefully. For instance, if someone scrolled to see only 5 stories and didn’t even see content below it, is it worth teaching our models that the story at 8th position (which user didn’t even see) was a bad story for the user?
- Generating labels for models in a multi-stage ranking gets even trickier (we’d dedicate a full post to it in the future)
That’s it — at least when it comes to the semantics of generating training data. Depending on the scale, the volume of training data may be huge, and that creates all the usual challenges in terms of logging, storing, and manipulating this data.
Conclusion
That’s it — this post covers feature logging and training data generation. As you can see, there is a tremendous amount of complexity in both stages. And while these stages are less glamorous than both the serving side (which has lots of low latency distributed system problems) and the actual modeling (which has deep ML problems), these two stages actually underpin everything else and deserve a lot more attention than they usually get.
Next, we will cover the very last stage — modeling in a dedicated post. Stay tuned!