Training a collaborative filtering based recommendation system on a toy dataset is a sophomore-year project in colleges these days. But where the rubber meets the road is building such a system at scale, deploying in production, and serving live requests within a few hundred milliseconds while the user is waiting for the page to load. To build a system like this, engineers have to make decisions spanning multiple moving layers like:
- High-level paradigms (like collaborative filtering, content based recommendations, vector search, model based recommendations)
- ML algorithms (e.g., GBDTs, SVD, Multi tower neural networks, etc.)
- Modeling libraries (e.g., PyTorch, Tensorflow, XGBoost)
- Data management (e.g., choice of DB, caching strategy, reuse primary database or copy all the data in another system optimized for recommendation workload, etc.) [1]
- Feature management (e.g., offline vs online, precompute vs serve live)
- Serving systems (performance, query latency, distribution model, fault tolerance, etc.)
- Deployment system (e.g., how does new code get updated, build steps, keeping caches working after processes restart, etc.)
- Hardware (e.g., GPUs, SSDs)
No wonder architecting a system like this is a daunting task. Thankfully though, after years of trial and error, FAANG and other top tech companies have independently converged on a common architecture for building/deploying production-grade recommendation systems. Further, this architecture is domain/vertical agnostic and can power all sorts of applications under the sun — from e-commerce and feeds to search, notifications, email marketing, etc.
The goal of this publication is to start from the basics, explain nuances of all the moving layers, and describe this universal recommendation system architecture.
We will start with a post to explain the serving side of this architecture at a high level, quickly followed by a post about the training side — these two posts will mostly outline the structure and identify the key scaling problems in serving and training, respectively. (Edit, we ended up writing two follow-ups to this post — part 2 about training data generation here and part 3 about modeling here). Future posts will go through these scaling issues one by one and describe how they are typically solved, along with the best practices developed over years of learning. So let’s get started:
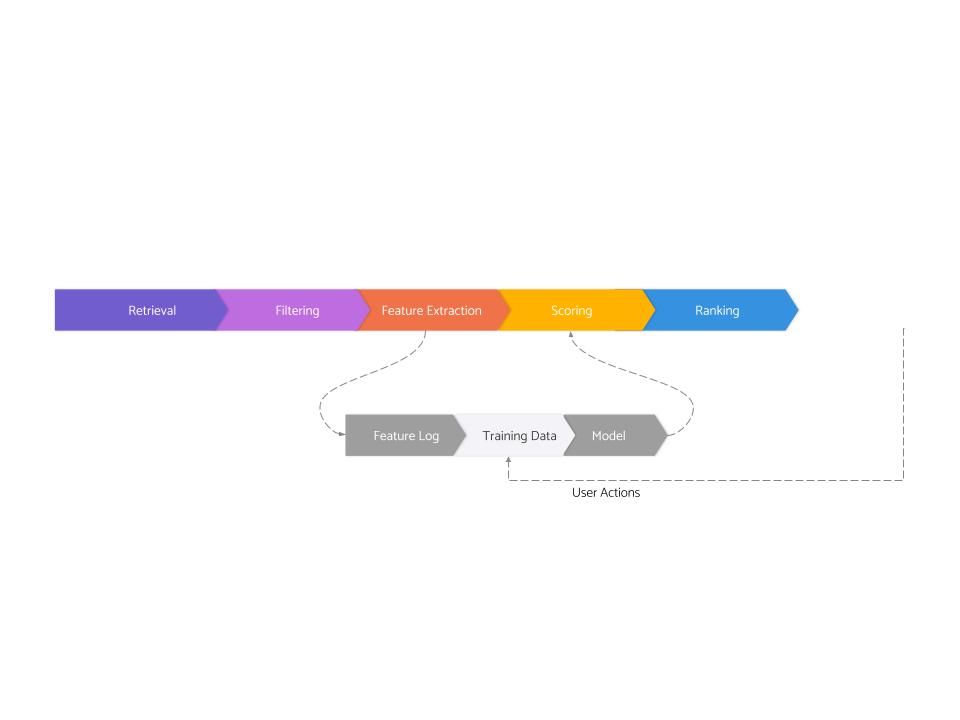
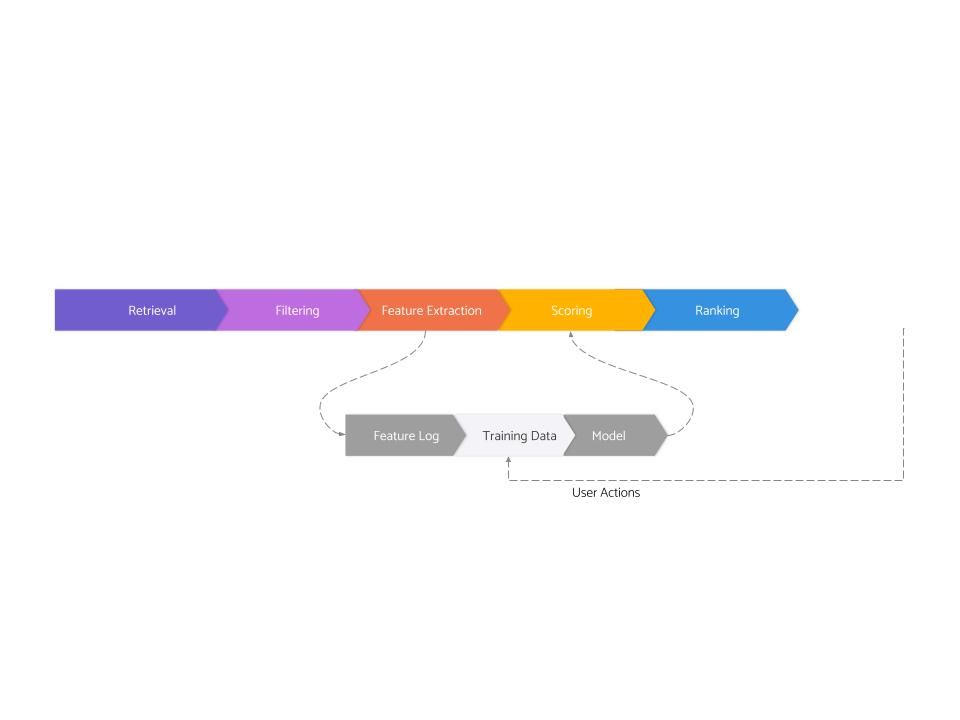
Modern recommendation systems are composed of eight (somewhat overlapping) logical stages:
- Retrieval
- Filtering
- Feature Extraction
- Scoring
- Ranking
- Feature Logging
- Training Data Generation
- Model Training
The first five of these are related to serving, and the last three are related to training.
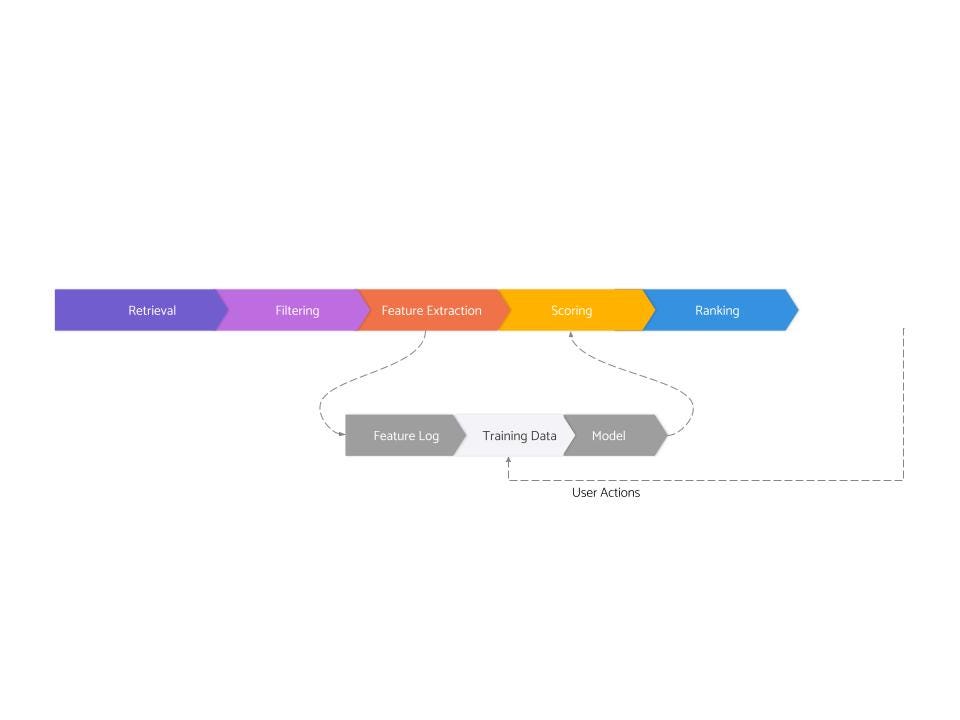
Let’s go through all the serving layers one by one:
1. Retrieval
Products like Facebook have millions of things to show in any recommendation unit - so many that it’s physically impossible to score all of them using any ML model while the user is waiting for their feed to load. So instead of scoring each item in the inventory, a more manageable subset of the inventory is first obtained via a process called Retrieval or “Candidate Generation” (since it generates candidates for ranking).
Retrieval is not just a FAANG scale problem — since the user is waiting for the “page” to load, most recommendation requests have a budget of only 500ms or so, and it is only possible to score a few hundred items in a request. As a result, whenever the inventory is a couple thousand items or more (which covers a large % of all real-world systems), a retrieval phase is needed.
How does Retrieval work? Retrieval is done by writing a few heuristics, also called as “candidate generators” or simply “generators”, each of which selects, say a dozen or so distinct candidates. Some common examples of generators are:
- Content that is trending in a user’s geography in the last x hours
- Recent content from authors/topics that the user explicitly “follows”
- Find 5 contents that user “liked” in the past, and for each such content, find 5 more “related” items
- Find the most relevant topics for a user and find the freshest content from each of the topics.
Retrieval can be powered by ML (e.g., trained embeddings), but more often than not, a larger % of generators are mere heuristics that encode some “product thinking” about what content is likely to create a good recommendation experience. And by writing a few of these and taking a union of all their candidates, we ensure that the system is able to at least consider all sorts of interesting inventory. Retrieval has only two jobs — 1) get all the interesting things (or at least as many as possible) [2] and 2) get as few total things as possible so that we can score/examine each candidate using the power of ML.
2. Filtering
After retrieving a few hundred candidates, recommendation systems typically filter out “invalid inventory”. For instance, if you’re building a social network, you might want to filter out things that are likely to be spammy. Or if you are building a video OTT platform, you may have to do some geo-licensing-based filtering. Or if you’re building an e-commerce product, you may have to filter things that are out of stock. Filters can also be extremely personalized, some examples:
-
Some products try to filter out content that the user has already seen before
-
Some products expose some controls to the users to hide away topics or authors or other sources of content
In short, most real-world recommendation systems develop a long list of filters over time, which once again encode some product thinking about what creates a good experience. [3]
Filtering and retrieval have a very interesting relationship. Some filters are pushed down to the generators themselves — for instance, if you’re building a dating product, filters for location and sexual preferences may be a part of each generator itself. But more often than not, it is physically impossible to have each generator respect each filter at the source, and so a whole layer of filtering is needed.
3. Feature Extraction
After filtering, we have a slightly smaller list of candidates — but it’s still going to be a couple hundred candidates long. We somehow need to choose the top ten items to show to the user. As you can imagine, this is going to involve some sort of scoring — for instance, in a job portal, we may want to compute how close is the job’s salary range to the user’s desired salary range.
But before any scoring can even begin, we need to obtain a bunch of data about each item that is going to be scored. In the job portal example, we will need the salary range of each candidate's job. Such signals about candidates are called “features”. Features are not just about the candidates but also include data about the user (e.g., user’s desired salary range). In fact, some of the most important features in literally every single recommendation system are those that capture users’ interaction behavior with potential candidates - this is so important and so nuanced that we will dedicate a whole post on this topic in this blog soon. Either way, we have a few hundred candidates, and we extract a bunch of features (which are basically just pieces of data) about the candidates and the user. Usually, we get anywhere between a few dozen to hundreds of features per candidate.
It is worth pausing here and letting the scale sink in for a minute - we have a few hundred candidates, say 1000, and we get a few dozen features about each candidate, say 100 — we need to fetch 1000x100 or 100K pieces of data from some database in only 500ms (the latency budget of a recommendation request). And note that you don’t even have to be at FAANG scale to run into this problem - even if you have a small inventory (say a few thousand items) and a few dozen features, you’d still run into this problem. And fetching and computing so much data is an incredibly hard infra problem to solve and as a result, creates huge limitations on how “expressive” the features can actually be.
4. Scoring
So far, we have narrowed down the full inventory to a few hundred candidates and extracted a few dozen features about each. Now comes the bit where we use all the extracted features to assign a score to each candidate. In the simplest systems, the scoring phase is pretty rudimentary, often just a handcrafted formula that mixes a bunch of features of interest (e.g “let’s divide the number of likes by the number of impressions and give a boost by doubling the score if the user follows the content author”). But very soon, these handcrafted formulae and rules start hitting “corner cases” and creating bad experiences. That is where ML kicks in - a machine learning model is trained that takes in all these dozens of features and spits out a score (details on how such a model is trained to be covered in the next post).
There are two key ideas that are very successful and present in the scoring of most real-world recommendation systems (and we’d write dedicated posts about both in the future — stay tuned):
- Multi-stage scoring — not all ML models are equal, and some are lot “heavier” than others. And it is usually not possible to run the heaviest ML models on hundreds of candidates. So instead, scoring itself is broken down in two substages — 1st stage scoring (which uses a relatively lighter ML model like GBDTs on all 500 candidates and emits out, say, top 100 candidates) and the 2nd stage scoring, which runs the heavy model (say deep neural network) on just the top 100 candidates.
- Combining many models — ML models can only learn whatever we teach them to learn. And typically, they are taught to predict the probability of user engaging in a single action, say like. Sorting all content by what gets clicked is a good start but has lots of issues — for instance, it might only distribute clickbaity content. To make the recommendations more balanced, usually, multiple models are trained - say, one for predicting clicks, one for predicting comments, one for user reporting the content, etc. And the final score of a candidate is a weighted average of all these models. While this makes the recommendations better, this can also increase the amount of computation that needs to be done. [4]
5. Ranking
Once scores have been computed for every candidate, the system moves on to the very last step — ranking. In the simplest systems, this stage is as simple as sorting all the candidates on their scores and just taking the top K. But in more complicated systems, the scores themselves are perturbed using non-ML business rules. For instance, it is a common requirement across many products to diversify the results a bit — for instance, not show content from the same publisher/author one after another. There are many algorithms for such diversification, but most of them operate in a similar fashion by adjusting the scores to respect the diversity (e.g., demote scores if successive items are not diverse enough).
In addition to score perturbation, it is a common practice to run all the items against all the filters once again at this stage to avoid any embarrassing failures. For instance, maybe some of the candidate generators are a bit stale and don’t know that an item has gone out of stock — it’s better to filter it out here instead of sending an item to the user that they can’t even purchase.
Finally, once top K items are chosen, they are handed to some sort of “delivery” system which is responsible for things like pagination, caching, etc.
Conclusion
That’s it! These are the five serving stages of real-world recommendation systems. As you can see, even if a recommendation system is trained, deploying that in production is incredibly hard. In the next post, we will look at the training side of the recommendation system. And in the subsequent posts, we will go through all the infra/scaling issues outlined here and share how they are typically solved — stay tuned!
Managing data is surprisingly hard for real-world recommendation systems because of extreme needs on all three of write throughput, read throughput, and read latencies. As a result, primary databases (e.g., MySQL, MongoDB, etc.) almost never work out of the box (unless you put in a lot of work to scale them in a clever way) ↩︎
Often bloom filters are used to filter out content already “seen” by the users ↩︎
This is actually fairly true across all the stages — 80% of decisions & iterations in building a recommendation system are all about product-specific needs & business rules, not machine learning. ↩︎
This technique is called “value modeling” - value model is an expression (typically weighted linear sum) of ML models with each term describing a specific kind of value to the user. ↩︎