Realtime Feature Platform. Beautifully Built.
Fennel helps you author, compute, store, serve, monitor & govern both realtime and batch ML features.
Incredibly easy to install and use.
Ship Features 100x Faster. Yes, 100x.
Real Python. No DSLs.
No DSL, no Spark or Flink jobs. Plain old Python & Pandas means zero learning curve for you.
Automatic Backfills
Pipelines backfill automatically on declaration - no more pesky one off scripts.
Fully-Managed Infrastructure
Fennel brings up & manages everything that is needed - zero dependencies on your prod infra.
Feature repository for reuse
Write standardized features once, share & reuse across all your use cases.
Best-in-class data quality tooling
No more feature or data bugs
Strong Typing
Catch typing bugs at compile time and at source of data, thanks to strong typing.
Immutability & Versioning
Immutable & versioned features to eliminate offline online skew due to definition changes.
Unit Testing
Prevent unforced errors by writing unit tests across batch & realtime pipelines.
Compile Time Validation
Strict end to end lineage validation at compile time to prevent runtime errors.
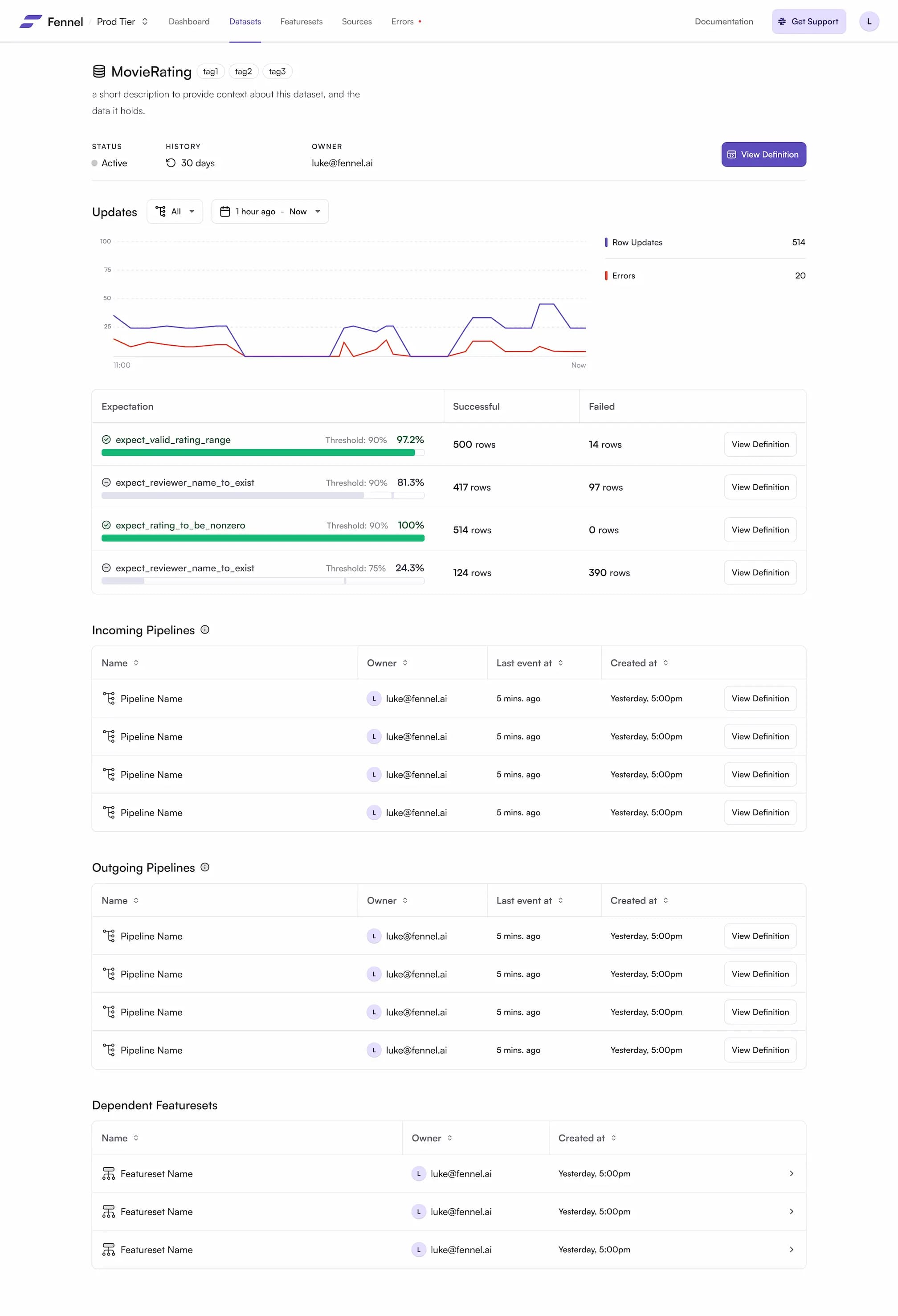
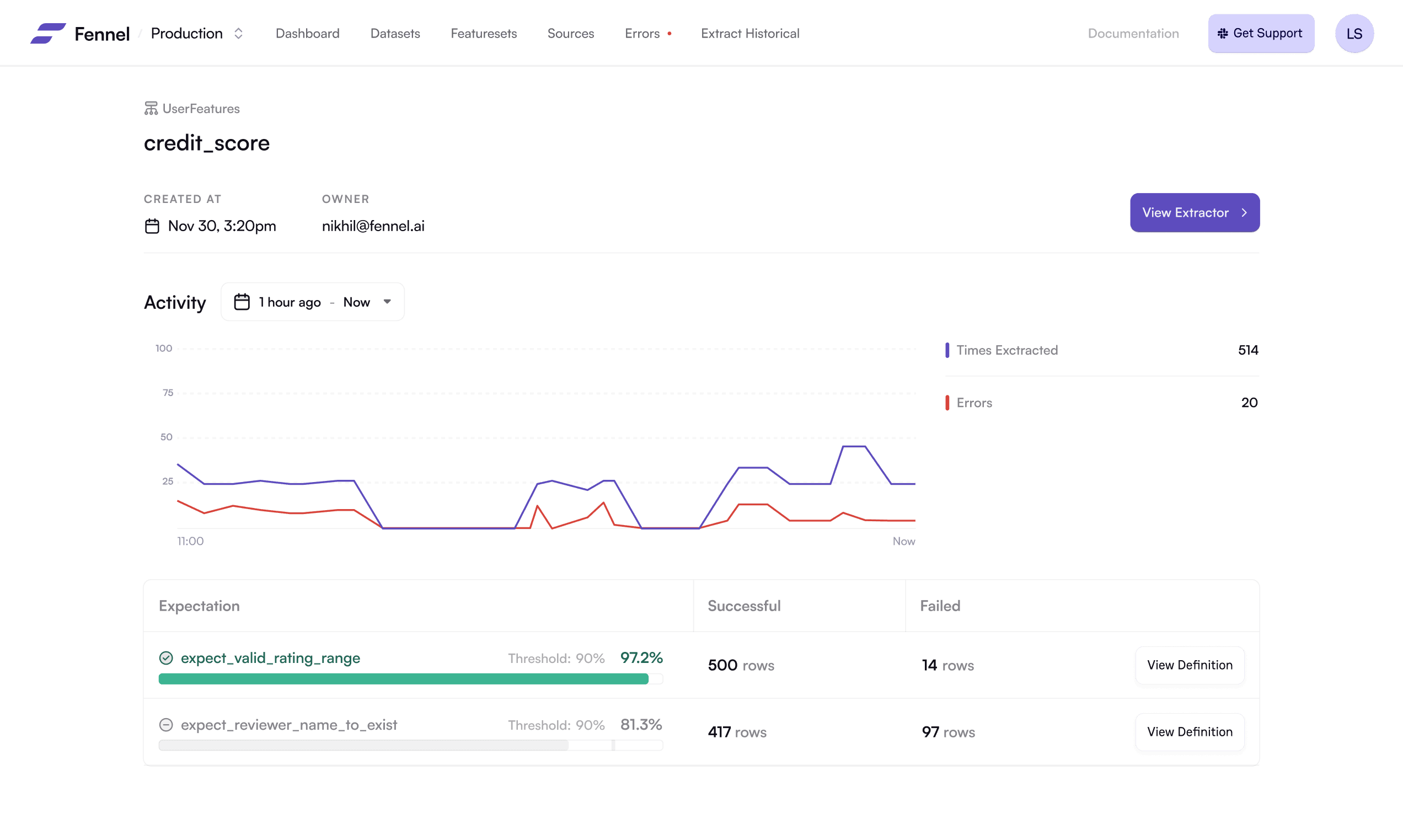
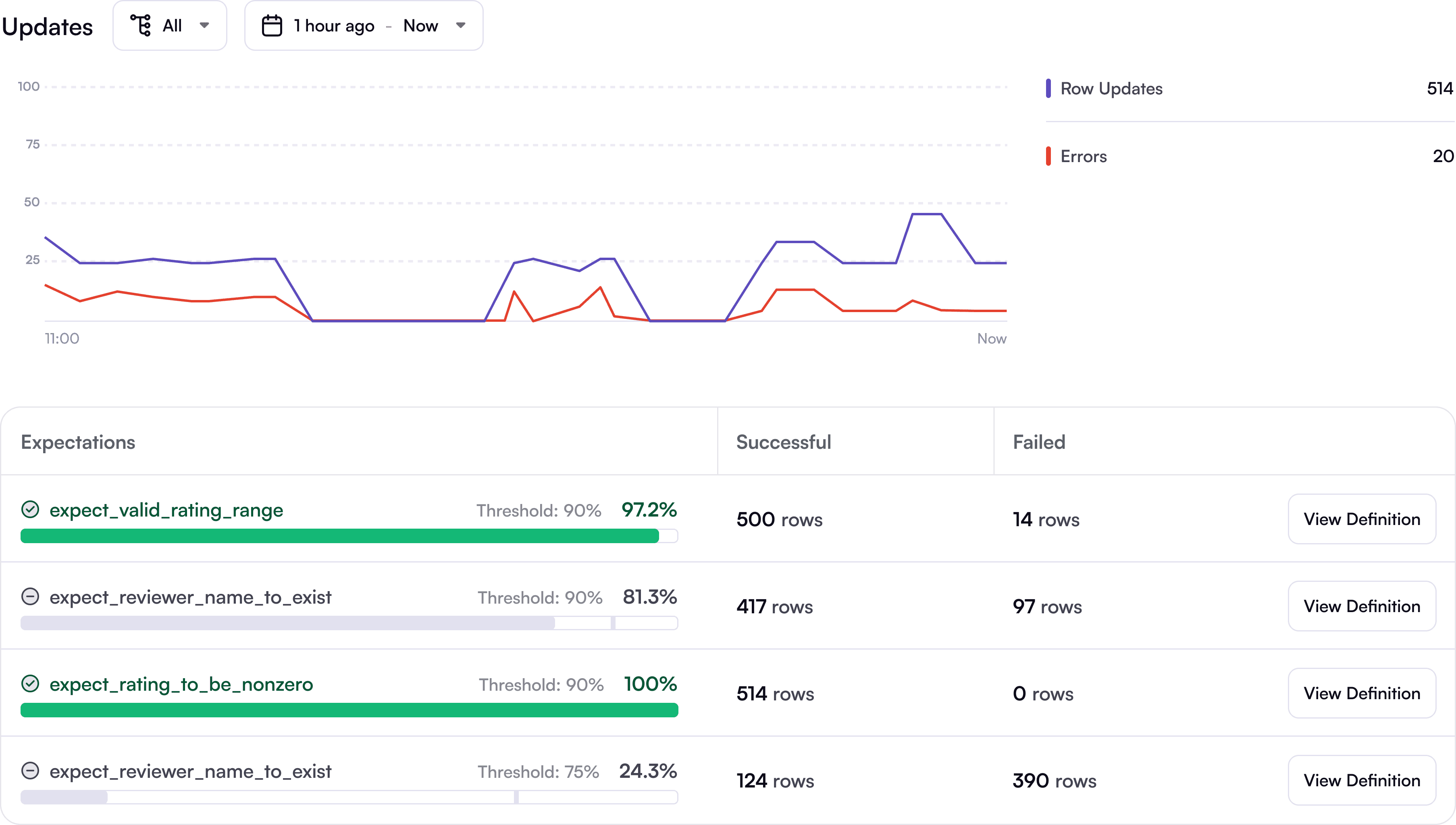
Data Expectation
Specify expected data distributions, get alerted when things go wrong.
Online / Offline Skew
Single definition of feature across both offline and online scenarios.
Unprecedented Power
Temporally correct streaming joins
No more stale data
Sub-second Feature Freshness
Single-digit ms response
Ultra-low Latency Serving
How it works
Read & Write Path Separation
The right abstraction for realtime feature engineering
Bring your Data
Use built-in connectors to effortlessly bring all your data to Fennel.
Derive Data via Streaming Pipelines
Define Features
Query via the REST API
1postgres = Postgres(host=...<credentials>...)
2kafka = Kafka(...<credentials>...)
3
4
5@dataset
6@source(postgres.table("user_info", cursor="signup_time"), every="1m")
7@meta(owner="[email protected]", tags=["PII"])
8class User:
9 uid: int = field(key=True)
10 dob: datetime
11 country: str
12 signup_time: datetime = field(timestamp=True)
13
14
15@dataset
16@source(kafka.topic('transactions'))
17@meta(owner="[email protected]")
18class Transaction:
19 uid: int
20 amount: float
21 payment_country: str
22 merchant_id: int
23 timestamp: datetimeRust
The primary language of our backend, relying heavily on Tokio's async runtime
Kafka
Handles all inflow data. All streaming jobs read and write to Kafka.
RocksDB
Handles all at-rest data, with some also offloaded to Redis.
Pandas
Used as the dataframe interface between user-written code and the server.
gRPC
Used alongside Protobufs to write services and exchange data.
Kubernetes
For maintaining the lifecycle of all running services.
Pulumi
Used for provisioning Fennel infrastructure as code.
PostgreSQL
Used as a central metadata store, with the exception of customer data.
Experience the Slickest Feature Engineering Workflow